Design Hybrid AI Deployment Around Data Synchronization First
Design hybrid AI deployment as a data synchronization problem first. Learn architectures, patterns, and workflows to keep models coherent across environments.
Your biggest risk in hybrid AI deployment isn’t vendor lock-in or Kubernetes strategy. It’s your own models quietly disagreeing with each other because they’re looking at different versions of reality.
In most enterprises, hybrid AI means some models in the cloud, some running on on prem infrastructure, maybe a few edge AI deployment pilots in branches or devices. Everyone celebrates the architecture diagrams. Then, months later, a customer gets three different credit limits depending on whether they ask in-app, at the branch, or via call center.
The root cause is almost never "the model is bad." It’s that data, features, and model versions aren’t synchronized. Data synchronization and data consistency were treated as plumbing details instead of the core design problem.
Our thesis in this article is simple: you only get reliable, scalable hybrid AI if you design around synchronization and coherence requirements from day one. Hybrid isn’t just a connectivity decision between cloud and on prem; it’s a distributed systems problem where AI models are the most visible casualty of hidden inconsistency.
We’ll walk through what hybrid actually means in practice, how inconsistency shows up in production, how to define synchronization requirements, which consistency models to use, and the core patterns and reference architecture for a synchronization-designed hybrid AI deployment. Along the way, we’ll show how to turn this into concrete hybrid AI deployment strategy for data consistency instead of slideware.
At Buzzi.ai, we design and implement hybrid AI platforms with data synchronization and observability built in, not bolted on. This guide distills what we’ve learned building enterprise hybrid AI deployments with data synchronization across regulated and fast-moving industries.
Hybrid AI Deployment: Why It’s a Data Problem, Not Just Infra
What hybrid AI deployment actually means in the enterprise
In the real world, hybrid AI deployment means your AI workloads are spread across cloud, on prem infrastructure, and sometimes edge. But they’re still expected to behave like a single, coherent system. The website uses a cloud-based recommendation model, the branch uses an on-prem risk scoring engine, and the mobile app calls an API that might run in either, depending on latency.
That’s different from a standard cloud AI setup where everything assumes a centralized data platform and a single serving environment. In a pure-cloud world, consistency is largely an internal problem: if your feature store is wrong, it’s wrong for everyone in the same way. In hybrid, inconsistency is asymmetric: some environments are wrong, some are right, and nobody can tell which is which.
Why do enterprises embrace enterprise hybrid ai deployment if it’s so hard? Because reality forces them to. Data residency and sovereignty laws keep certain data in-country or in-datacenter. Latency constraints mean fraud models must run close to the point of swipe. Legacy systems still live in on-prem cores. Cost pressure pushes heavy training to cloud while keeping low-latency inference close to the transaction.
Consider a bank. Its core ledger and customer master live in an on-prem mainframe. Its advanced credit risk and fraud analytics run in cloud, where scalable GPUs and data lakes sit. For a loan application, the decision blends on-prem systems of record with cloud-native models. That entanglement is what makes multi cloud and hybrid powerful—and what makes data synchronization non-negotiable.
How today’s hybrid projects go wrong
Most hybrid projects start as infrastructure plans: "We’ll keep system of record on prem, spin up analytics in cloud, maybe use edge gateways." Everything looks neat in Visio. The problems start when the same customer gets different answers from different channels.
Common failure modes include:
- Inconsistent predictions between regions or channels (e.g., branch vs app).
- Stale features on-prem because the last batch sync failed silently.
- Business rules implemented differently in different environments.
These are not primarily model-quality issues; they’re data inconsistency issues. The same model, with the same code, can behave differently if the feature values differ by a few hours, or if one environment is missing an input column.
Imagine a customer limit calculator that’s supposed to be global. The mobile app, calling the cloud, gives a credit limit of $15,000. The branch terminal, calling an on-prem scoring engine with older salary data, says $10,000. Nobody sees the divergence until the customer complains. At that point, your hybrid ai deployment strategy for data consistency becomes a firefighting strategy.
The business impact is brutal: loss of trust in "the AI", failed audits when regulators see inconsistent decisions, and a growing pile of hidden technical debt. Every disagreement between systems becomes a production incident waiting to happen.
Reframing hybrid as a coherence engineering challenge
The way out is to reframe hybrid from an infra choice to a data coherence engineering challenge. A synchronization-designed hybrid AI deployment starts by asking: What has to be the same, where, and how quickly?
In the typical infra-first approach, the sequence is: choose cloud vendor, design VPN and Kubernetes clusters, then worry about data sync as an implementation detail. In a synchronization-first approach, the sequence flips: define data consistency and synchronization requirements, then design the topology and tooling that can satisfy them.
That means you don’t pick your hybrid ai deployment stack before you know which decisions can tolerate lag, which require strong guarantees, and how regulations constrain data movement. The tooling is downstream of the synchronization model, not the other way around.
Once you think of hybrid AI as coherence engineering, everything snaps into place: you start designing around feature freshness SLOs, transaction boundaries, and clear sources of truth. The next sections will walk through how inconsistency shows up in production and how to prevent it by design.

How Data Inconsistency Breaks Hybrid AI in Production
What hybrid inconsistency looks like in the real world
In production, data inconsistency rarely announces itself with a clean error. It shows up as subtle discrepancies: slightly different risk scores, prices that don’t match across channels, personalized offers that feel random.

Take a retailer or telecom. The website calls a cloud-based recommendation API that uses a real-time stream of user behavior. The in-store or in-branch system runs on older on-prem software that only syncs customer events nightly. For the same customer, the site recommends a premium upgrade; the store POS shows a generic offer because it’s operating on a snapshot from yesterday.
Under the hood, the root causes are often:
- Stale features in one replica of the feature store.
- Delayed batch syncs that miss certain low latency inference signals.
- Partial event streams where some environments miss updates entirely.
Online/offline reconciliation adds another layer: your training data might represent one reality, while your production environment lives in another. Models trained on a "clean" offline snapshot will behave oddly when fed a skewed live feature distribution from an unsynchronized environment.
Silent drift between environments
The nastiest problems come from silent drift. Your feature store in cloud and your on-prem copy started coherent. Over time, differences creep in: a field added in cloud but not mirrored on prem, a change data capture job that lags under peak load, a one-way data replication process that misses deletes.
Similarly, your model registry might promote version 3 of a model to cloud, but on prem is still serving version 2 because someone forgot to update a deployment pipeline. Inference caches in edge or branch systems may continue serving predictions made with old models even after an update.
In regulated industries, this isn’t just annoying; it’s a governance problem. Decisions in one jurisdiction may be made on unsynchronized data copies, violating residency rules or internal policies. When auditors ask "Which data and model version was used for this decision?", you need data lineage and clear governance and compliance stories for each environment.
Imagine a compliance team discovering that on-prem credit risk decisions used older customer income data than the cloud system, changing outcomes for a subset of applicants. Now every declined loan in that window is potentially in scope for review.
Why ‘disagreeing AIs’ destroy trust and ROI
Once business stakeholders see different answers for the same input, they don’t debug your feature pipelines; they just stop trusting the whole system. "The AI is wrong" is often shorthand for "the AI is inconsistent." That’s why hybrid ai deployment without a strong data synchronization strategy quietly erodes ROI.
The cost impact multiplies quickly:
- Duplicated debugging efforts across teams and environments.
- Emergency patching and ad-hoc rollbacks when inconsistencies hit customers.
- Parallel manual processes kept alive "just in case" the AI disagrees with itself.
It’s cheaper to invest upfront in synchronization-first design than to diagnose emergent inconsistent behavior later. As one hypothetical CIO might say: "We didn’t buy AI to get three different versions of the truth; we bought it to get one." Synchronization-designed hybrid AI is how you deliver that single, coherent truth.
Defining Synchronization Requirements for Hybrid AI
Start with decisions, not databases
The most reliable way to figure out how to design hybrid ai architecture with data synchronization is to start from decisions, not systems. List the critical AI-assisted decisions your organization makes: approve a loan, route a support ticket, trigger a fraud review, recommend an upsell.
For each decision, ask three questions:
- Where does this decision happen (cloud, on prem, edge)?
- What data and features does it depend on?
- Within what time bounds must those inputs be consistent across locations?
This gives you transaction boundaries and decision scopes. A per-transaction fraud decision might need near-real-time consistency for a specific card; a monthly risk report can tolerate lag. The art of a robust hybrid ai deployment strategy for data consistency is matching synchronization guarantees to each decision’s risk and latency needs.
Picture a distributed loan approval workflow: the mobile app collects data (edge), the branch officer reviews and adds context (on prem), and the cloud risk engine provides a probability of default. Unless you design synchronization so that both branch and cloud see the same applicant profile within a defined window, you will get divergent decisions.
Latency, availability, and consistency trade-offs
Behind every hybrid system sits an uncomfortable truth: across distributed systems, you can’t maximize latency, availability, and data consistency at the same time. You pick trade-offs. The CAP theorem is often overused, but the intuition is right: in a partitioned, multi-region, multi-environment world, you decide what to sacrifice in which scenarios.
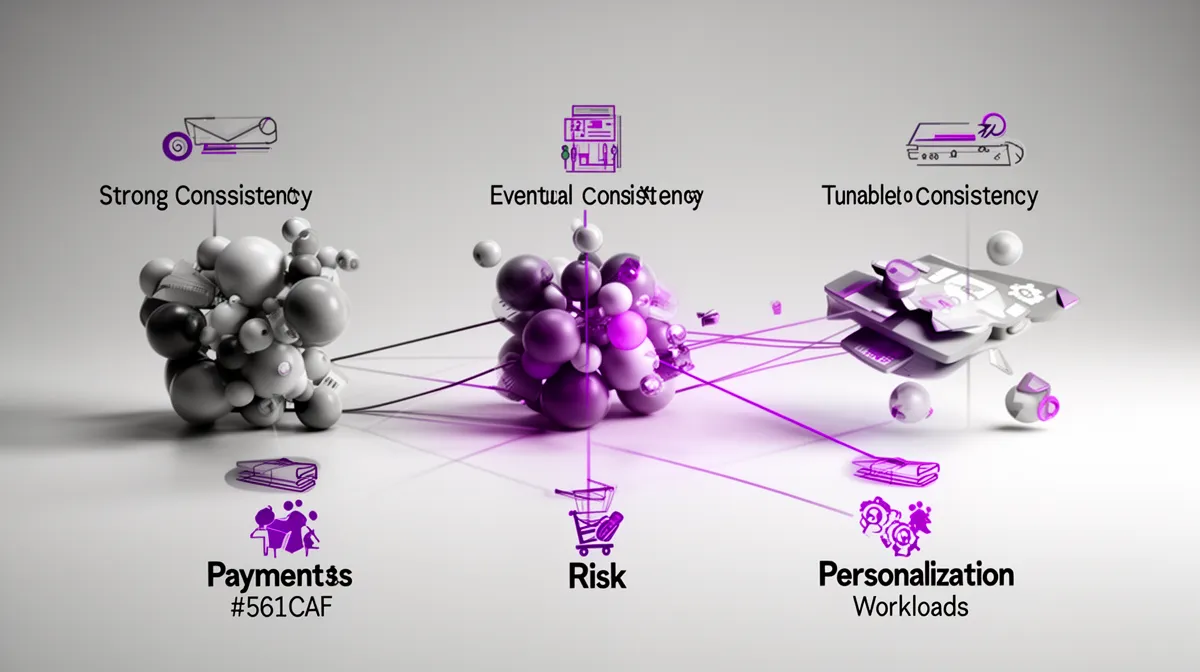
In practice, that means choosing between:
- Strong consistency: all environments see the same write before proceeding.
- Eventual consistency: replicas converge over time, but reads may see older data.
- Tunable consistency: per-operation or per-region choices about how many replicas must agree.
For fraud detection and other low latency inference workloads, you often accept slightly weaker global consistency in exchange for speed within a local domain. For monthly risk models or marketing analytics, eventual consistency is fine as long as you define a reconciliation window. For payments or regulatory reporting, you might need near strong consistency, even across multi cloud and on-prem environments.
Thinking explicitly about consistency models for multi cloud and on prem ai deployment turns vague reliability requirements into concrete SLOs: "This feature must be consistent within 2 seconds across regions for card transactions" is something you can engineer and test.
Regulatory and data residency constraints
Any serious enterprise hybrid AI deployment runs into data residency and sovereignty constraints. GDPR, HIPAA, and similar regulations limit what data can cross borders or leave specific environments. This directly shapes your data synchronization design.
The nuance is that you don’t always need to synchronize raw data across environments. Often, you can synchronize features, aggregates, or model parameters instead. That distinction matters for governance and compliance: a European customer’s raw PII may never leave the EU data center, but a feature like "days since last delinquency" might.
For regulated industries, this means encoding residency and governance constraints into your synchronization architecture rather than retrofitting them later. A European vs US data center pair might use regional feature computation with limited cross-border sharing of anonymized aggregates. That design choice affects where models train, where they infer, and how your enterprise hybrid ai deployment evolves over time.
Regulators themselves are starting to publish guidance on cross-border data flows—see, for example, official GDPR resources on data transfers. Your architecture needs to line up with these requirements by default, not as an afterthought.
Choosing Consistency Models for Hybrid AI Workloads
When you need strong consistency across environments
Strong consistency means that once a write is acknowledged, every environment that matters for a decision sees that write before making a dependent decision. In human terms: nobody should be able to approve a loan based on "yesterday’s" salary if today’s update has been stored elsewhere.
This level of guarantee is usually required for:
- Payments and settlement workflows.
- Identity verification and access control.
- High-risk compliance decisions with legal consequences.
The trade-off is clear: stronger guarantees often mean higher latency, more coordination between cloud and on prem infrastructure, and stricter failure modes (e.g., blocking writes during partitions). But if a transaction’s outcome can’t depend on where it was initiated, these costs are justified.
Think of a KYC (Know Your Customer) flow where customer risk flags must be globally consistent at transaction time. If a branch in one country clears a customer while a cloud-based service still sees them as blocked, you’ve just turned a synchronization bug into a compliance risk.
Where eventual consistency is not only acceptable but optimal
For many AI workloads, insisting on strong consistency is overkill. Eventual consistency means that replicas will converge given time, but you allow some temporary divergence. Crucially, it doesn’t mean "never consistent"; it means "consistent within a defined window."
This model fits:
- Personalization and recommendations.
- Content ranking and feed algorithms.
- Marketing automation and campaign triggers.
- Batch analytics and reporting.
For a recommendation system, a 5–10 minute lag in behavioral features rarely breaks user experience. In fact, relaxing consistency lets you build more resilient streaming data pipelines and avoid coupling feature computation to every edge environment. You still need clear online offline reconciliation policies, but you don’t need to block the world on a feature update.
Eventual consistency is often the optimal choice because it reduces operational fragility and cost. The key is to define SLOs around how eventual is acceptable: "Personalization features must converge across environments within 15 minutes" is a very different guarantee than "whenever we get to it."
Tunable consistency and mixed strategies
Real systems rarely live at one extreme. Tunable consistency lets you choose, per operation or per region, how strict you want to be. This is where hybrid AI gets interesting: you can combine consistency models inside a single logical system.
A practical pattern is to enforce strong consistency for core identity and financial data, while using eventual consistency for behavioral features. For example, "current account balance" must be synchronized immediately across cloud and on prem, but "number of app opens last week" can lag.
Making this work in consistency models for multi cloud and on prem ai deployment requires explicit policy. You define which fields and feature groups get which guarantees, and you encode that in your data platform, APIs, and infrastructure. Without explicit policy, your engineers will reinvent ad-hoc consistency decisions on every project.
Done well, this mixed strategy aligns data consistency with business value. The riskiest decisions get the strictest guarantees; everything else benefits from cheaper, more flexible synchronization.
Synchronization Patterns for Hybrid AI and ML Systems
Event-driven architecture as your synchronization backbone
If synchronization is the goal, event driven architecture is your best backbone. Instead of relying on ad-hoc batch jobs and nightly dumps, you stream changes as they happen using change data capture (CDC) from on-prem systems into cloud and edge.
Events flowing through a bus like Kafka or a managed streaming service become the canonical log of "what happened". Downstream consumers—feature pipelines, model-serving services, edge caches—subscribe and update themselves in near real time. Idempotent consumers ensure that if events are replayed or duplicated, your state still converges.
API gateway and service mesh layers wrap these streams and services with governance: access control, rate limiting, and observability across hybrid domains. This is where hybrid mlops deployment with cross environment synchronization becomes practical: every environment observes the same event stream, with environment-specific consumers.
Modern streaming platforms document these patterns extensively—for example, Kafka’s documentation covers CDC and hybrid event-driven topologies you can adapt to your own stack.
Keeping feature stores coherent across cloud and on prem
The feature store is where synchronization success or failure becomes visible to models. A coherent feature store strategy across cloud and on prem is non-negotiable if you want consistent predictions.
Common replication strategies include:
- Write-once, serve-many: features computed centrally (often in cloud) and replicated read-only to on-prem and edge.
- Regionally sharded: features computed locally per region or DC, with limited cross-region aggregation.
- Hub-and-spoke: a central hub reconciles and redistributes features from multiple spokes.
Conflicts arise when multiple environments can write to the same feature. Here, concepts like conflict free replicated data types (CRDTs) can help design data replication structures that converge automatically. Academic work on CRDTs—such as the foundational papers you can find via research repositories like ACM—shows how to design mergeable data types that don’t lose information.
Equally important is schema and definition governance. Versioned feature definitions, with clear ownership and rollout processes, prevent subtle data consistency bugs where "customer_ltv" means different things in different places. Without that, your synchronization patterns for hybrid ai and ml systems will still leak inconsistency through semantics.
Synchronizing model registries, deployments, and inference caches
Data isn’t the only thing that must stay in sync. Your model registry, deployment pipelines, and inference caches also need coherent synchronization.
A robust mlops pipeline will:
- Promote models through dev, staging, and prod with clear versioning and signatures.
- Mirror the model registry across cloud and on-prem clusters.
- Deploy models in lockstep to all relevant endpoints, including edge.
In a hybrid setting, hybrid mlops deployment with cross environment synchronization means your CI/CD system treats cloud and on-prem clusters as first-class citizens in the same release workflow. When model v3 passes validation, it’s rolled out or canaried consistently to both environments, with guardrails and rollbacks that consider data and cache state.
Inference caches complicate this: if a branch system caches predictions for performance, you must design cache invalidation when models or key features change. Otherwise, you’ll have environments returning pre-v3 predictions long after the rest of the system has moved on.
Dealing with conflicts and reconciliation
Even with perfect intent, hybrid systems will generate conflicts. Two environments may trigger overlapping decisions based on slightly different inputs. Data updates may arrive out of order. The question is not "Can we avoid conflicts?" but "How do we resolve them predictably?"
Standard tools include:
- Online/offline reconciliation jobs that compare states and correct discrepancies.
- Audit logs and data lineage that trace how a decision was made and on which data.
- Clear conflict resolution policies: which environment is the source of truth in which scenarios.
For long-running, distributed AI-driven workflows, the saga pattern is a useful mental model. Instead of a single global transaction, you orchestrate a sequence of local transactions with compensating actions when steps fail or conflict. For example, if fraud flags are raised in both cloud and on prem, you reconcile them into a single case entity and apply downstream actions only once.
This is where synchronization stops being "just data" and becomes part of your business process design. Architecting these patterns up front pays off every time a hybrid interaction behaves as one coherent flow instead of a collection of brittle integrations.
As you build these patterns, the workloads themselves can span from conversational AI agents to analytics. For example, our predictive analytics and forecasting solutions often run in hybrid topologies, and we design their synchronization patterns carefully to avoid silent drift.
Synchronization-First Hybrid AI Reference Architecture
Core layers of a synchronization-designed architecture
Now let’s assemble these ideas into a concrete hybrid ai architecture. A synchronization-designed stack usually has the following layers:
- Data ingestion / CDC: taps into source systems (often on prem) and streams changes.
- Streaming / event bus: the backbone that carries events across environments.
- Feature store: computes and serves features with explicit freshness and consistency guarantees.
- Model registry: manages versions, metadata, and promotion workflows.
- Serving layer: APIs and services that expose models to applications in cloud, on prem, and edge.
- Governance / observability: logs, metrics, tracing, and policy enforcement.
Each layer is instrumented with metadata: timestamps, source IDs, versioning, data lineage tags. That’s how you implement a synchronization designed hybrid ai deployment instead of a pile of services. You know which feature version was used, which model version served the prediction, and how long it took an event to propagate.
Cloud usually hosts heavy analytics, model training, and global feature computations. On prem infrastructure hosts systems of record and high-sensitivity inference. Edge nodes handle ultra-low-latency inferences or local workflows. The trick is that they all plug into the same synchronization fabric.
Authoritative cloud providers publish hybrid and multi-cloud data synchronization patterns like these; your task is to adapt them with AI-specific layers for features, models, and decisions.
Operational workflows across training, staging, and production
Architecture is only half the story. The other half is how you operate it via mlops pipelines and workflows. Synchronization requirements must carry through from training to staging to production.
In training, you ensure your offline datasets reflect the same feature definitions and data domains that production uses. In staging, you validate not just model metrics but also data schema compatibility and synchronization behavior: does this feature propagate correctly to all environments within the SLO?
In production, hybrid mlops deployment with cross environment synchronization means your CI/CD releases models in coordinated fashion, with canary releases that span cloud and on prem. Rollback procedures must include data and features, not just model binaries. If a new feature definition causes divergence in one environment, you need to roll back the entire decision stack coherently.
Authoritative MLOps best practices emphasize versioning, rollbacks, and CI/CD, but in hybrid AI you apply them across multiple environments as a single logical unit.
Observability and drift monitoring for data coherence
A synchronization-first architecture isn’t complete without strong observability. You need to monitor and alert on synchronization drift, not just CPU or latency.
Key metrics and alerts include:
- Data freshness per environment (e.g., max feature lag in seconds or minutes).
- Feature parity rates (e.g., percentage of entities with identical feature vectors across environments).
- Model version parity (e.g., proportion of requests served by the latest approved model).
- Cross-environment decision divergence (e.g., how often sandbox comparisons disagree).
This is where observability, data coherence, and data lineage converge. With proper logging and audit trails, you can answer: "What did we know, when, and where?" for any decision. That’s vital for governance and compliance and for debugging subtle synchronization issues before they become incidents.
A well-designed dashboard might highlight, for example, the max feature lag between cloud and on prem, the percentage of decisions made on outdated models, and the rate of prediction divergence across mirrored environments. Those are the leading indicators that tell you whether your hybrid AI platform is staying in sync.
How Buzzi.ai Delivers Synchronization-Designed Hybrid AI
Methodology: synchronization requirements first
At Buzzi.ai, we start hybrid projects where most teams end: with synchronization requirements. Our AI discovery and architecture assessment process maps your key decisions, data domains, and consistency requirements before we talk about vendors.
From there, we derive architecture blueprints, synchronization patterns, and hybrid ai deployment strategy for data consistency that align with your governance and regulatory needs. Rather than forcing a one-size-fits-all platform, we design an enterprise hybrid ai deployment with data synchronization that reflects how your business actually operates.
In one anonymized engagement, we worked with a financial institution whose cloud and on-prem risk systems had started to drift. By explicitly modeling synchronization scopes and rebuilding their event-driven backbone, we prevented cross-environment drift by design instead of chasing it with ad-hoc fixes.
Platform and implementation capabilities
We don’t just design; we build. Buzzi.ai implements hybrid ai platform with built in data synchronization capabilities: event-driven integration, feature store design, hybrid model serving, and end-to-end monitoring.
On top of that, we deliver AI workloads—AI agents, workflow automation, ai implementation services for predictive analytics, and more—that run across cloud, on prem, and edge. Synchronization is not an add-on for these workloads; it’s an assumption baked into the architecture.
For regulated sectors like financial services and healthcare, we align these capabilities with strict governance and compliance and data residency requirements. The result is an enterprise ai solutions stack you can explain to regulators, auditors, and your own risk committee without hand-waving.
De-risking your next hybrid AI initiative
If you already have a hybrid AI deployment, the biggest risk is what you can’t see: silent synchronization drift. We help enterprises run readiness assessments, PoCs, and phased rollouts focused specifically on synchronization risks.
Our ai readiness assessment and broader ai transformation services look for misaligned feature stores, inconsistent model registries, and missing observability. We then define a roadmap to a hybrid ai deployment strategy for data consistency that reduces operational surprises.
In one case, we identified that an existing deployment’s on-prem scoring engine was still using an older feature version for a key risk input. Fixing that single synchronization gap eliminated a whole class of mysterious discrepancies that had been plaguing the team for months.
Conclusion: Treat Hybrid AI as a Synchronization Problem
When hybrid AI fails, it’s rarely because you chose the "wrong" cloud or container platform. It fails because you treated hybrid as an infra choice instead of a data synchronization and coherence problem. Once your models start disagreeing across environments, trust and ROI evaporate quickly.
The way forward is to define synchronization requirements from decisions and regulations first, then design architecture, consistency models, and MLOps workflows that satisfy them. Different workloads demand different consistency guarantees, and a synchronization-designed architecture bakes in observability, lineage, and drift monitoring from the start.
If you’re planning or already operating a hybrid AI platform, this is the right moment to audit it for synchronization risks. Map your decisions, check your feature and model parity, and stress-test your event-driven backbone. If you’d like a partner that’s built synchronization-first hybrid AI before, schedule a discovery session with Buzzi.ai and we’ll help you design—or validate—a hybrid AI architecture that actually stays in sync.
FAQ
What is hybrid AI deployment and how is it different from standard cloud AI?
Hybrid AI deployment means running AI workloads across a mix of cloud, on-prem, and sometimes edge environments that must behave like one coherent system. Standard cloud AI assumes a centralized environment where data and models live in one place. Hybrid adds complexity because data, features, and models must be synchronized across locations while still meeting latency, cost, and regulatory constraints.
Why do hybrid AI deployments fail without a strong data synchronization strategy?
Without a strong data synchronization strategy, each environment drifts: feature stores get out of sync, model versions diverge, and caches return stale predictions. The result is "disagreeing AIs"—the same input producing different outputs depending on channel or region. That inconsistency destroys trust, complicates audits, and generates ongoing technical debt that’s far more expensive than designing synchronization up front.
How can I detect and troubleshoot data inconsistency between cloud and on-prem AI systems?
Start by instrumenting metrics for data freshness, feature parity, and model version parity across environments. Then, run mirrored or shadow traffic through both cloud and on-prem systems and measure decision divergence for the same inputs. Combined with strong logging and data lineage, this lets you pinpoint whether inconsistencies stem from stale features, missing events, or misaligned deployments.
Which consistency models should I use for different hybrid AI workloads?
Use strong consistency for high-risk, transaction-level decisions like payments, KYC checks, and legal compliance reporting, where outcomes can’t depend on where a request originated. Eventual consistency suits personalization, recommendations, and analytics that tolerate some lag as long as replicas converge within a defined window. Many enterprises adopt tunable consistency, applying strong guarantees to core identity data and looser guarantees to behavioral features, based on business risk and latency needs.
How do I keep feature stores synchronized across cloud and on-prem environments?
Design your feature store as part of a streaming, event-driven architecture where changes flow via CDC and event buses instead of ad-hoc batch jobs. Choose a replication strategy (write-once, serve-many; regional shards; or hub-and-spoke) and define clear ownership and conflict resolution rules. Version feature definitions, enforce schema governance, and monitor feature parity and freshness across environments to catch drift early.
What are best practices for hybrid MLOps deployment and model versioning?
Best practices include a centralized (but mirrored) model registry, strict versioning and signing policies, and CI/CD pipelines that treat cloud and on-prem clusters as part of the same release unit. Canary releases should span all relevant environments, and rollback procedures must account for data and cache state, not just model binaries. For a deeper assessment of your current setup, Buzzi.ai’s AI discovery and architecture assessment can help identify and fix cross-environment synchronization gaps.
How do governance, compliance, and data residency affect hybrid AI architecture?
Governance, compliance, and data residency rules determine where data can live, how it can move, and which environments can participate in decisions. In practice, this shapes whether you synchronize raw data, derived features, or only model parameters between regions. A compliant hybrid AI architecture encodes these constraints into its synchronization design so that every decision is traceable and explainable to regulators.
What metrics should I monitor to catch synchronization drift in hybrid AI systems?
Track feature freshness (lag between environments), feature parity (percentage of entities with matching feature vectors), model version parity (share of traffic served by the current model), and cross-environment decision divergence. Complement these with infrastructure-level metrics on event backlog and CDC delays. Together, they provide an early-warning system before drift becomes customer-visible or triggers compliance issues.
How can I reconcile conflicting AI predictions made in different environments?
First, define a source-of-truth policy: in which scenarios does cloud, on-prem, or edge take precedence? Then, implement reconciliation jobs and audit logs that merge conflicting predictions into a single case or outcome. For long-running workflows, use saga-style orchestration so that compensating actions can roll back or adjust decisions when conflicts are detected.
How does Buzzi.ai approach synchronization-designed hybrid AI deployment for enterprises?
Buzzi.ai starts with decision and data-mapping via an AI discovery phase, capturing consistency, latency, and regulatory requirements before proposing any tools. We then design and implement a synchronization-first architecture—event streams, feature stores, model registries, and observability—that spans cloud, on-prem, and edge. Finally, we help you operate it with hybrid MLOps practices, so your AI stays in sync even as models, data, and regulations evolve.


