The Ultimate Enterprise RAG Solution for a Governed Knowledge Fabric
Design an enterprise RAG solution as a secure knowledge fabric with governed, auditable answers across systems. Learn key architecture and vendor steps.

Your biggest AI risk isn’t hallucination—it’s letting critical knowledge remain locked across dozens of tools where no one can reliably find, trust, or audit it. The promise of an enterprise RAG solution (retrieval augmented generation) is not "yet another chatbot," but a governed knowledge layer that sits on top of everything you already use.
Done right, this becomes an enterprise knowledge fabric: a secure, searchable, and auditable mesh of content that can answer questions, show its work, and respect every access rule your compliance team cares about. It upgrades enterprise search, knowledge bases, and internal assistants into a single, consistent capability.
Executives don’t buy chatbots; they buy risk reduction, productivity, and control. A modern retrieval augmented generation stack addresses all three—if you treat it as core enterprise knowledge management, not a side experiment. That’s the shift we’ll walk through: architecture, governance, evaluation, and vendor choice.
At Buzzi.ai, we design and implement these RAG fabrics as production systems, not demos. We’ll show how to connect your existing tools, enforce governance, and roll out a secure enterprise RAG solution that your IT, security, and business teams can all stand behind.
Beyond Chatbots: What an Enterprise RAG Solution Really Solves
From Siloed Systems to a Unified Knowledge Fabric
Most enterprises already have the pieces of a great knowledge system—SharePoint, Confluence, ticketing tools, file shares, CRM, and email archives. The problem is that no one knows which system to search, and every team curates its own partial truth.
An effective enterprise RAG solution doesn’t rip and replace these tools. Instead, it overlays them with a governed enterprise knowledge fabric that can index, normalize, and retrieve content in place. Where basic enterprise search stops at document links, RAG composes contextual answers grounded in what it retrieves.
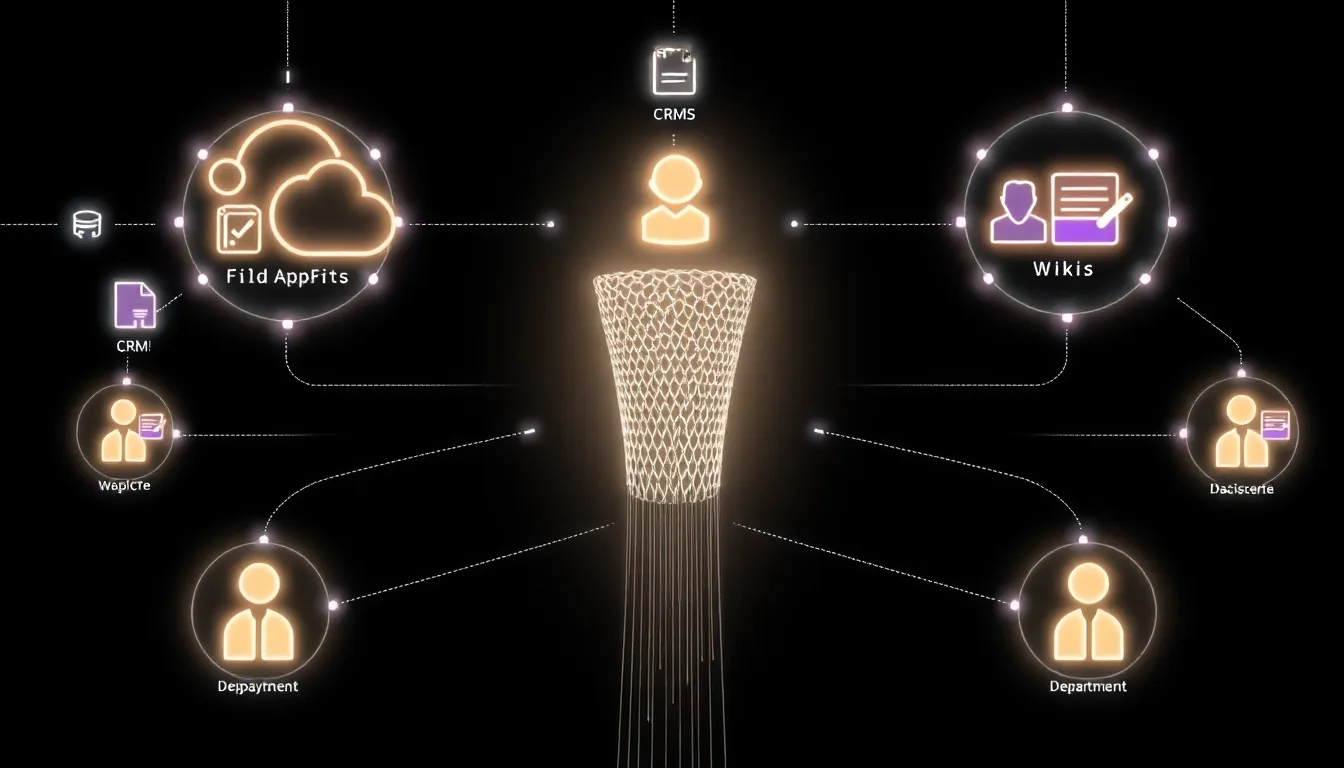
Under the hood, this means using semantic search and hybrid retrieval (combining embeddings with keyword and metadata filters) to pull the right passages from across your landscape. HR, Legal, and Support can all query the same knowledge layer, but see only what they’re entitled to see.
Because retrieval is live, you’re not fighting brittle, periodically synced knowledge bases. As policies change and new documents land, the knowledge fabric updates automatically without content teams constantly copying text into FAQ portals.
Business Outcomes: Compliance, Productivity, and Risk Reduction
The payoff shows up in metrics executives already track: reduced time-to-answer, fewer escalations, shorter onboarding, and lower support costs. A best enterprise RAG solution for secure internal knowledge search turns ad-hoc tribal knowledge into repeatable, measurable flows.
Consider an employee with a nuanced policy question. In the old world, they try email, SharePoint, or a PDF on a shared drive—and maybe forward something out of date. With an internal RAG assistant, they ask once, get a synthesized answer, see citations, and can click into the underlying documents, all with a clear audit trail.
Governed RAG also reduces shadow AI risk: instead of pasting sensitive data into public LLMs, employees use an internal assistant that enforces llm governance and logs interactions. For a sense of what’s possible at scale, look at how leaders in enterprise AI are evolving internal search and assistant strategies in their latest enterprise search and knowledge reports.
As you scale, this becomes a backbone capability for use cases you might recognize from your own roadmap—or from other firms’ enterprise AI case studies.
RAG vs Traditional Enterprise Search and Static Knowledge Bases
Traditional enterprise search is fundamentally keyword-based: it matches words in your query to words in documents. Static knowledge bases and FAQ portals go one step further, but still force users to hunt and interpret.
With retrieval augmented generation, semantic search and relevance scoring identify the best chunks; the LLM then composes a direct answer within a constrained context window. You get responses written in natural language, grounded in the retrieved passages instead of the model’s pre-training.
| Traditional Search | RAG-Powered Answering |
|---|---|
| Returns a ranked list of links | Returns a synthesized answer with citations |
| Relies on keyword matches | Uses semantic search and embeddings |
| Hard to enforce consistency | Central policies and system prompts |
| Poor at multi-document questions | Designed to compose across many sources |
That said, RAG is not a hammer for every nail. For simple lookups—"open the latest Q3 report"—plain search may be enough. The right mental model is RAG as a backbone capability that multiple interfaces (search box, assistant, workflow tools) can reuse, not just a single chatbot front-end.
Reference Architecture: Designing a Scalable Enterprise RAG Solution
Core Building Blocks: Ingestion, Vector Databases, and LLMs
A production-grade enterprise RAG architecture follows a clear set of building blocks. Connectors pull content from M365, Google Workspace, Confluence, ticketing tools, CRM, and file shares into a monitored knowledge ingestion pipeline.
Documents go through normalization, document chunking, and enrichment before being stored in a vector database and traditional index for content indexing. At query time, hybrid retrieval combines semantic search with keyword and metadata filters to maximize relevance and compliance.
The LLM layer then performs retrieval augmented generation over the retrieved chunks, governed by system prompts and policies. An API and orchestration layer exposes this as a reusable capability for search, agents, and workflow tools.

In practice, that might mean connectors into Microsoft 365, ServiceNow, Salesforce, and internal file systems; a managed vector DB; and a policy engine enforcing hybrid retrieval rules. The key is observability—ingestion status, error handling, and drift monitoring are first-class citizens, not afterthoughts.
Multi-Domain and Multi-Tenant Design for Large Organizations
Large organizations rarely want a single, flat index. Instead, they need a shared platform with per-domain collections (HR, Legal, Support, Product) and clear boundaries between them—essentially a multi-tenant architecture inside the enterprise.
A secure enterprise RAG solution with role-based access control combines per-domain indices with organization-wide policies. Role-based access control and attribute-based rules decide which indices your query can touch and which chunks you’re allowed to see.
Global companies may run separate regional indices to respect data residency, with cross-region aggregation where allowed. Deployment can be cloud, VPC, or fully on-premise deployment for the most regulated environments, all integrated with SSO.
Integrating with Existing Enterprise Systems and Controls
An enterprise knowledge fabric RAG platform for large organizations should plug into your identity provider (SSO/IdP) so that existing groups and roles drive access centrally. That same identity context flows through to enforcement in the retrieval layer.
For security teams, the RAG stack should integrate with DLP, CASB, and SIEM for monitoring and incident response. Every query and answer can be logged, with sensitive events surfaced into SOC workflows via your SIEM.
Content connectors and APIs index major SaaS and on-premise systems without bypassing current governance. The RAG layer respects, rather than replaces, your existing enterprise knowledge management and enterprise search controls.
Governance, Security, and Auditability in Enterprise RAG
Data Governance: Lineage, PII Redaction, and Access Control
For risk and compliance teams, governance starts with data lineage. Every chunk in your index should know which system, document, version, and owner it came from.
Before content enters the pipeline, pii redaction and field-level security strip or mask sensitive fields, especially for HR and customer data. Fine-grained access control at index, document, and chunk levels then ensures that even within a shared platform, users see only what they are permitted to see via role-based access control.
These patterns are foundational to llm governance because they control what the model can possibly retrieve and reference. Without them, you’re effectively giving the model a blind copy of everything.
Provenance Tracking and Audit Trails for Regulated Industries
Regulated industries need more than good answers; they need proof. An enterprise RAG solution with provenance tracking and audit trails links every answer back to specific documents, versions, and timestamps.
At query time, the system records who asked what, which sources were retrieved, and which were actually cited. Those events become part of an immutable audit trail that compliance teams can review.
In the UI, this looks like an answer pane with citations, source icons, and timestamps, alongside an expandable audit log showing the underlying retrieval and ranking decisions. Frameworks like the NIST AI Risk Management Framework increasingly expect this level of transparency.
Operational Guardrails: Prompt Engineering and Model Grounding
Governance is not just about data; it’s also about behavior. Prompt engineering and model grounding patterns ensure the LLM sticks to retrieved context, refuses to speculate, and always cites sources.
System prompts can encode rules such as "answer only from provided context" or "if information is missing, say you don’t know." Safety filters, content policies, and continuous evaluation with rag evaluation metrics close the loop.
Many enterprises now route this work through AI risk committees to align with broader how to implement an enterprise RAG solution with governance initiatives. It’s where technical guardrails and corporate policy meet.
Measuring Quality and Selecting the Right Enterprise RAG Vendor
RAG Evaluation Metrics and Test Sets
To evaluate enterprise RAG solutions and vendors objectively, you need a shared test set and clear metrics. That means pulling real tickets, emails, and FAQs from your environment and defining what a correct, grounded answer looks like.
Key rag evaluation metrics include answer correctness, grounding quality, citation coverage, retrieval relevance scoring, latency, and coverage across domains. You can measure these offline with human raters and online via A/B tests and user feedback.
As content and models evolve, monitor drift—are answers still grounded in the right sources, or is performance degrading? This is classic enterprise knowledge management, now with an ML twist, and research such as the original Retrieval-Augmented Generation paper provides useful baselines.
Vendor Checklist: What Enterprise RAG Platforms Must Provide
When comparing platforms, build a simple checklist for how to evaluate enterprise RAG solutions and vendors rather than relying on demos. At minimum, your shortlist should provide robust governance, RBAC, provenance, deployment options, integrations, SLAs, and support.
For regulated industries, demand detailed audit logs, data residency controls, and certifications like SOC 2 or ISO 27001. A secure enterprise RAG solution with role-based access control is non-negotiable if sensitive data is involved.
Run bake-offs or pilots with the same test set across vendors, scoring them on quality, latency, governance, and integration effort. This is also where implementation partners like Buzzi.ai can help you interpret results and design an enterprise knowledge fabric RAG platform for large organizations that fits your stack.

Roadmap: From Pilot to Production Knowledge Fabric
Adopting RAG is a journey, not a single project. A pragmatic roadmap for how to implement an enterprise RAG solution with governance starts with discovery and scoping, then a pilot in one domain (often Customer Support), followed by expansion into more units, and finally an enterprise-wide fabric.
Over 90–180 days, you might move from a focused support assistant to HR, Legal, and Product use cases, sharing one governed platform underneath. Change management—communication, training, success stories, and feedback channels—is as important as the technology.
Throughout, you need ongoing operations: monitoring, content lifecycle management, retraining, and governance reviews. Partners like Buzzi.ai provide enterprise RAG implementation services across this lifecycle, not just an initial proof of concept.
Conclusion: Building Your Governed Knowledge Fabric
When you treat RAG as a backbone, not a bot, you get something more powerful than another interface. You get a governed enterprise knowledge fabric that unifies siloed systems into trusted, queryable answers.
A solid enterprise RAG solution architecture spans ingestion, retrieval, governance, security, and integration with existing controls. Provenance tracking, data lineage, and auditability are table stakes for regulated enterprises, not optional extras.
With the right rag evaluation metrics, vendor checklist, and phased rollout, you can de-risk adoption and align with IT and compliance from day one. If you’re ready to design a secure, auditable knowledge fabric for your organization, explore Buzzi.ai enterprise RAG & knowledge fabric implementation services and let’s scope a pilot that fits your stack and governance needs.


