Data Engineering for AI: The 80% That Decides If You Ship
Most AI projects fail at the data layer. Learn how to prioritize data engineering for AI, structure teams, and fund pipelines that actually ship ROI.
Your next AI project will not fail because the model was 2% worse than state-of-the-art. It will fail because a CSV changed, a field went missing, or data from one critical system silently stopped updating—and nobody noticed until customers did. If you’ve lived through a flaky recommendation engine or a “smart” chatbot that got dumber over time, you’ve already felt the cost of weak data engineering for AI.
In slides and demos, AI looks like models and magic. In production, AI looks like data contracts, schemas, lineage, and on-call rotations. The uncomfortable reality is that in most ai project lifecycles, 70–80% of the real work and risk sits in upstream data engineering, not in model choice.
This article is about funding and designing that upstream work properly. We’ll unpack why most AI failures are really data failures, what modern data engineering for AI projects actually includes, how to allocate budget and headcount, and how to design architectures that don’t crumble when reality changes. We’ll also walk through practical roadmaps and show how we at Buzzi.ai lead with data-engineering-first, not model theatrics.
Why AI Projects Really Fail: It’s the Data Engineering, Not the Model
Executives rarely kill AI projects because “we chose the wrong optimizer.” They kill them because the demo was great, but the production system was unreliable, opaque, and impossible to debug. That gap almost always traces back to fragile or missing data engineering for AI projects, not some subtle shortfall in modeling sophistication.

From Impressive POCs to Fragile Production Systems
The pattern is depressingly consistent. A team builds an impressive proof-of-concept on a curated dataset: exports from two core systems, manually cleaned, with a well-behaved schema. The model works beautifully in the sandbox. Then it meets real production data.
In production data pipelines, fields go null, optional parameters become required, new product lines appear, and “temporary” workarounds live forever. Without robust data quality checks and data observability, these changes slip through. The model’s outputs degrade, but by the time model monitoring catches the issue (if it exists at all), customers are already seeing bad recommendations or false fraud alerts.
Consider a fraud model trained on last year’s transaction formats. It goes live and performs well—until the business launches a new payment method and tweaks the transaction schema. Suddenly, some fields are always missing or mis-mapped. The model starts flagging the wrong customers. From the outside it looks like “the AI is broken.” In reality, weak data quality controls and brittle ETL caused the failure.
The Hidden 80%: Where Time and Risk Actually Live
Ask any experienced practitioner where their time goes, and you’ll hear the same thing: data discovery, cleaning, integration, and governance dominate the calendar. Studies like Anaconda’s State of Data Science report routinely find that data prep takes more than half of project time; in real production AI systems, that proportion is often higher. The glamorous modeling phase is a relatively thin slice.
We can think of it as a misaligned funnel. Today, many organizations spend 30% of effort on data and 70% on model and UI “theatrics”—even when the underlying data is not trustworthy. In a healthy ai project lifecycle, that ratio should flip: roughly 70–80% of the effort goes into data engineering for AI and training data management, and 20–30% on modeling and integration.
This is also where data engineering vs data science in AI projects becomes non-negotiable. Data scientists and ML engineers are optimized for experimentation, modeling, and evaluation. Data engineers build and operate the systems that keep data flowing, consistent, and governed over time. When you ask scientists to paper over deep data issues, you’re effectively using surgeons as plumbers and then blaming them when the house floods.
Industry analysts like Gartner have repeatedly highlighted that a majority of AI initiatives stall or fail to reach production largely due to data issues—availability, quality, and integration. Academic and industry research similarly shows most ML project time is spent on data preparation rather than model building.[1][2]
Why BI-Grade Data Engineering Isn’t Enough for AI
Many leaders assume, “We already have a data warehouse and dashboards, so our data engineering must be fine.” That’s like saying, “We have paved roads, so we’re ready for Formula 1.” Data engineering for AI has different requirements from BI/analytics: lower latency, finer-grained history, labels, and much stricter handling of edge cases.
BI systems can tolerate some staleness and aggregation. A monthly revenue dashboard doesn’t collapse if one day’s data is late. But a credit risk model making real-time decisions on loan approvals is a different animal. It needs near real-time data validation, full history to capture behavior over time, and strong guarantees on how missing values are handled. Your data platform for AI has to support real-time data processing, robust schema evolution, and clear contracts that survive continuous change.
In other words, AI-grade engineering demands explicit data freshness SLAs, coverage thresholds, and well-defined behaviors for anomalies. You are no longer just summarizing the past; you are driving decisions in the present. The bar is higher.
What Data Engineering for AI Really Includes (Beyond ETL)
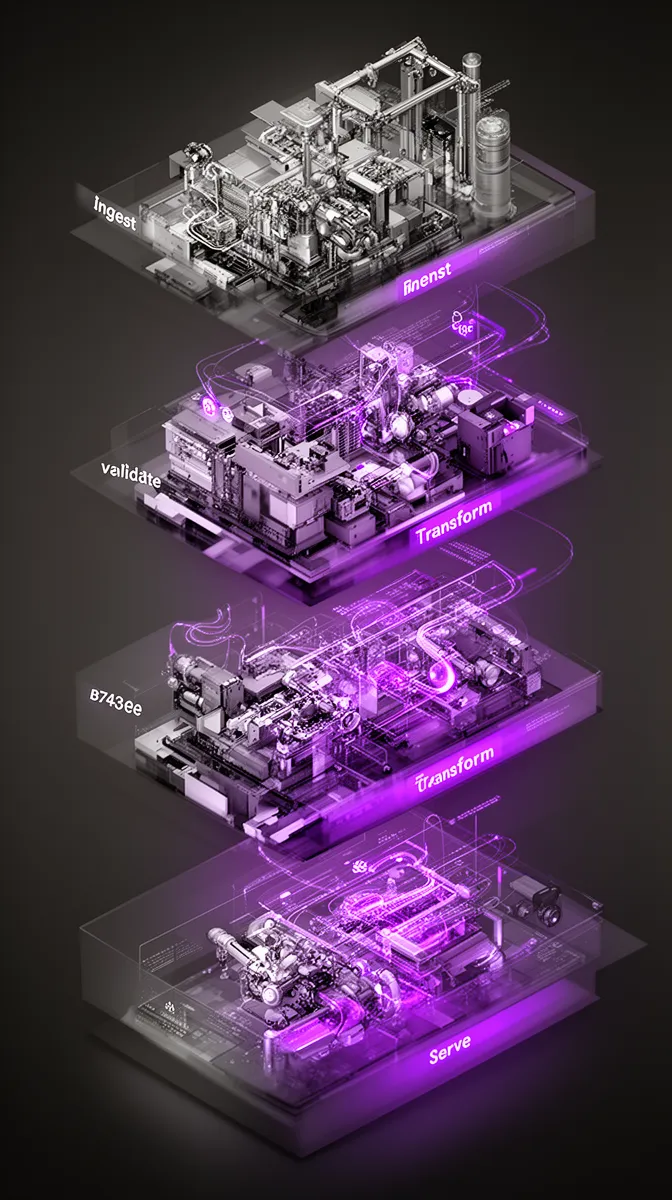
If you still equate data engineering with “write some ETL jobs into the warehouse,” you will underfund the parts of the system that matter most. Modern data engineering for AI covers ingest, validation, transformation, labeling, storage, serving, governance, and monitoring across the full lifecycle. It’s less about individual jobs and more about an integrated data platform for AI.
From Simple ETL to End-to-End AI Data Pipelines
For AI, a pipeline is more than extract-transform-load. We’re talking about a full machine learning data pipeline design: ingest from multiple sources, validate schemas and ranges, transform into model-ready representations, label where needed, and serve those features consistently to training and inference.
That includes both ETL and ELT patterns. Some data is better transformed close to the source; other data flows into a lake or warehouse first, where transformations run closer to storage. A robust pipeline will support both batch and real-time data processing depending on the use case, and will handle both structured and unstructured data (think log events plus support tickets).
Imagine a customer churn prediction system. Raw events come from web clickstreams, billing logs, CRM updates, and product telemetry. The pipeline ingests these streams, validates basic constraints, joins them into a coherent customer timeline, and aggregates them into features for models. Without well-designed data pipelines and etl and elt orchestration, your churn model will either be starved of data or polluted by silent inconsistencies.
Feature Engineering, Stores, and Reuse as Core Assets
In many organizations, feature engineering lives in notebooks and one-off scripts. Each new model reimplements the same logic with minor variations—and slightly different definitions. In AI-first companies, feature engineering becomes a product.
A feature store formalizes this. It provides a central, versioned catalog of features used in training and serving: “90-day purchase frequency,” “recency of last support ticket,” “average basket value by category.” By reusing these across models, you get consistent behavior in production AI systems, faster development cycles, and a clear, testable boundary between raw data and model inputs.
This is where training data management overlaps with scalable data architecture. The same logic that powers a churn model can power marketing optimization, upsell prediction, or risk scoring—if it’s engineered and stored for reuse rather than buried in ad-hoc code.
Governance, Lineage, and Observability as Non-Negotiables
As soon as AI systems make material decisions—approving loans, routing claims, prioritizing support—you need to answer basic questions: Where did this data come from? Who touched it? Is this pipeline still behaving as designed? That’s where data governance, data lineage, and data observability become foundational.
Governance covers access control, compliance, and policy. Lineage shows how a field in a model’s input traces back through transformations and sources. Observability instruments the pipelines with metrics and alerts: freshness, volume, anomalies, and drift. Organizations that treat these as optional quickly find themselves in firefighting mode when something breaks—and with no way to prove to auditors or regulators what went wrong.
Consider a sudden drop in model performance. With strong lineage, you can see that a particular upstream source changed its format three days ago, and one transformation started dropping 20% of rows. Without lineage and observability, teams may spend weeks debating whether the model “overfit” while the real issue is a silent schema change.[3]
AI-Specific Data Validation and Testing
In traditional software, we test code. In AI systems, we must test data as aggressively as we test code. That means schema checks, range checks, referential integrity, statistical tests, and drift detection wired directly into the pipelines.
Data validation frameworks can automatically detect when a field’s distribution shifts dramatically—say, an amount column that used to be in dollars is suddenly in cents. In a healthy mlops setup, those checks run as part of CI/CD, blocking bad data from entering training or inference environments.
These are core ai data engineering best practices: treat data contracts like APIs, version datasets and labels, and wire validation and model monitoring into the same deployment pipeline. That’s how you prevent one upstream mistake from corrupting weeks of training runs or quietly degrading production AI systems.
How to Allocate Budget, Time, and Talent: A Data-First AI Blueprint
Once you accept that data engineering for AI is the 80% that decides whether you ship, the next question is: how do you fund and staff it? This is where many organizations struggle. They want to move fast on models while quietly hoping their existing data stack will be “good enough.” It rarely is.
Target Ratios: 70–80% Data Engineering, 20–30% Modeling
For new initiatives, a simple rule of thumb works surprisingly well: allocate 70–80% of time and budget to data work, and 20–30% to modeling, integration, and UX. That includes pipeline design, data infrastructure, validation, data orchestration, observability, and governance.
Under-investing upstream is expensive. Every shortcut in data engineering for AI projects shows up later as operational incidents, fire drills, and crisis patches. In greenfield projects, lean even harder into data: building a robust resource allocation framework for data engineering in AI up front pays dividends across multiple future use cases. In retrofit projects, you may tolerate slightly skewed ratios as you adapt to legacy systems—but the goal remains the same.
Contrast two hypothetical programs with identical budgets. In a model-first approach, 30% is spent wrangling data “just enough,” 60% on modeling and UI, 10% on ops. In a data-first approach, 65% is spent on pipelines, platforms, and governance, 25% on modeling, 10% on ops. The first tends to produce impressive demos and fragile systems; the second tends to produce boring demos and reliable, compoundable assets.
A Practical Headcount Mix for AI Teams
Ratios aren’t only about money; they’re about people. For complex enterprise AI, we often see a healthy ratio of roughly 1.5–2 data engineers per ML engineer or data scientist. That mix ensures someone owns the data plumbing while others focus on models.
You also want adjacent roles: analytics engineers who translate BI and operational needs into reusable transformations, mlops engineers who own deployment and monitoring, and product managers who can prioritize use cases and trade-offs. The balance between data engineers vs ML engineers, and the presence of analytics engineering, often predicts whether an AI team spends its life shipping or stuck in endless “research.”
From our vantage point, successful teams tend to look like this: a core of data engineers and platform engineers building a data platform for AI, a smaller but focused group of ML engineers and scientists, and a product function that ensures work stays tied to business value. Failing teams are skewed heavily toward modeling talent with a thin or outsourced data function struggling to keep up.

Budgeting for Data Platforms, Not Just Models
Line items tell the story. If your AI budget is dominated by model development, consultants, and presentation layers, with a token allocation for cloud data warehouses, lakehouse architecture, and observability, you’re signaling that data engineering is optional. It isn’t.
A healthier budget explicitly funds ingestion/orchestration (Airflow, Dagster, event buses), storage/computation (scalable data architecture on warehouses and lakes), observability/governance (lineage, data observability, catalog), and modeling/serving. In a $1M AI program, it’s common for $600–700k to go into the data platform, with the remainder on models, UI, and integration.
This isn’t about buying tools for their own sake. It’s about funding the backbone that will support multiple AI systems. When teams treat data spend as foundational, they unlock reuse: the same investments support personalization, forecasting, risk, and more.
Executive Narrative: How to Sell a Data-First AI Plan
Non-technical leaders are understandably drawn to demos and outputs. Your job is to reframe the narrative around reliability, time-to-value, and risk. Instead of “We’re spending 70% on plumbing,” explain, “We’re building the data highways that every current and future AI initiative will run on.”
One simple before/after story: “Today, each AI project builds its own ad-hoc data feeds, which is why 60% stall before launch and 20% fail after. With a data-first plan, we’ll build governed, observable pipelines once and reuse them across three high-value AI products, cutting time-to-production in half and reducing incidents by 80%.” That’s an enterprise AI architecture story that boards understand.
Framed this way, funding how to prioritize data engineering for AI initiatives becomes a strategic, portfolio-level decision, not a line-item debate. You’re building infrastructure, not experiments.
Designing Data Architecture for Production-Grade AI
Architecture is where strategy meets reality. The best data engineering architecture for enterprise AI isn’t one specific vendor stack; it’s a set of patterns that balance flexibility, governance, and performance. Most mature organizations converge on some flavor of modern lakehouse, with clearly separated but well-connected layers for raw, curated, and feature data.
Core Patterns: Warehouse, Lake, and Lakehouse for AI
Traditional cloud data warehouses excel at structured analytics queries. Data lakes excel at storing cheap, large volumes of raw and semi-structured data. A lakehouse architecture combines the two: warehouse-style performance and governance on top of lake-style flexibility.
For AI workloads, this convergence matters. Models need historical raw data for experimentation, curated views for training, and fast access patterns for feature serving. A modern data platform for AI built on a lakehouse gives you that flexibility while keeping governance and cost in check. Major clouds like AWS, Azure, and GCP have all moved in this direction.[4]
The right architecture is the one whose latency, volume, and governance properties match your use cases. Reporting-only environments can get away with simpler stacks; real-time decisioning systems cannot.

Online vs Offline: Serving Features in Real Time
Another key distinction in enterprise AI architecture is offline vs online data. Offline stores hold large historical datasets for training and batch scoring. Online stores serve features with low latency to live models.
For example, a weekly demand forecasting model can happily train overnight on a warehouse and write results back into the warehouse. A fraud detection model, by contrast, needs sub-second access to up-to-date features for each transaction. That’s where online feature stores and carefully designed feature engineering pipelines come in.
Not every use case justifies real-time data processing. Over-engineering here is a common mistake. The goal is to align model deployment requirements with the right storage and serving patterns, and to keep training and serving data consistent enough to avoid training-serving skew.
Data Orchestration and MLOps: Connecting the Dots
Even the best-designed data layers and models are useless without connective tissue. Data orchestration tools manage dependencies and execution across pipelines: ingest, transform, feature build, training, and scoring. mlops platforms handle model versioning, deployment, and model monitoring.
In a robust setup, a nightly orchestration flow might pull fresh data into the lakehouse, rebuild key features, trigger model retraining if enough drift is detected, validate the new model, and then push it to production. Data lineage ties it all together: you can trace a prediction back to specific model versions and source datasets.
Without this end-to-end picture of the ai project lifecycle, you end up with brittle, manual glue that can’t keep up with change. Orchestration and MLOps aren’t add-ons; they are how you make architecture executable.
Security, Compliance, and Regional Constraints
The more powerful your AI systems become, the more important it is to get compliance right. Regulations like GDPR impose obligations on where and how you process personal data, how long you retain it, and how you obtain consent. GDPR-compliant AI development is fundamentally a data engineering and architecture challenge.
That means designing for data minimization, pseudonymization, region-aware storage, and fine-grained access control from day one. It’s also about having an auditable trail—through data governance and data lineage—that shows what data was used for which model and when. Official resources from authorities like the European Data Protection Board are clear: you must be able to explain and justify data processing for automated decision systems.[5]
Retrofitting consent tracking, residency, and security into an existing enterprise AI implementation is vastly more expensive than designing for it up front. Compliance is architecture.
Making It Real: Phased Data Roadmaps and Turnaround Playbooks
Even if you agree with all of this in principle, you still have a practical problem: where do you start, and how do you avoid boiling the ocean? The answer is to treat data engineering for AI as its own roadmap, with phases, milestones, and clear trade-offs. This is also where the right data engineering for AI consulting services can accelerate your path.
A 6–12 Month Data-Engineering-First Roadmap
A realistic 6–12 month roadmap has three phases. In months 0–3, you assess and win trust: inventory critical data sources, map existing data pipelines, and identify the biggest gaps in data quality, governance, and observability. You also choose 1–2 high-value AI use cases to focus the work—say, personalization and churn reduction for an e-commerce company.
In months 3–6, you build foundations: robust pipelines for those critical domains, initial feature libraries, and basic observability (data validation checks, freshness metrics, simple model monitoring). You start codifying ai data engineering best practices into templates and reusable components. Early models may go live, but they’re explicitly labeled as pilots.
In months 6–12, you scale and reuse: extend the platform to additional use cases, harden production AI systems, and refine your training data management processes. The goal is to transition from one-off projects to a sustainable, multi-product ai project lifecycle.
Prioritization Framework: Which Data Work Matters Now
Not all data work is equal. A simple framework helps you decide which pipelines to build or fix first: business value, data availability, complexity, dependencies, and regulatory risk. You score each candidate initiative across these dimensions and rank them.
For example, building a complex social-graph pipeline might be high value but also high complexity and low current data availability. Meanwhile, a transactional history pipeline might offer slightly lower upside but be easier and faster to deliver with existing data. In a sensible resource allocation framework for data engineering in AI, you’d tackle the transactional pipeline first.
For many organizations, the most leveraged investments are in shared primitives: customer 360 views, common event schemas, and unified identity resolution. These underpin multiple data platform for AI use cases and enterprise AI solutions.
Triage for Struggling AI Projects
If you already have AI projects in trouble, you don’t have the luxury of a clean slate. You need a turnaround playbook. Start by stabilizing inputs: freeze schema changes where possible, add basic data observability, and lock down critical data validation rules at pipeline boundaries.
Next, standardize schemas and contracts: define what each downstream consumer expects and enforce it. Only then revisit the models. This approach salvages sunk costs by addressing the real failure mode—data chaos—rather than endlessly tweaking hyperparameters in the face of moving targets.
Picture a fictional company whose recommendation engine had become erratic. Rather than building a new model, they paused modeling work and focused on three pipelines feeding product, user, and interaction data. By cleaning up data engineering for AI projects and hardening those pipelines, they restored stability to their production AI systems and doubled engagement. A later model refresh improved things further, but only because the foundation was finally solid.
Measuring "Good Enough" Data Engineering
You can’t improve what you can’t measure. “Good enough” data engineering is not a feeling; it’s a set of operational metrics. At minimum, track data freshness, coverage, pipeline failure rates, drift indicators, and lineage completeness.
For example, what percentage of critical tables meet your freshness SLA? What fraction of rows fail validation checks? How often do models trigger drift alerts, and how quickly do you respond? Over time, you want to correlate these metrics with business KPIs: churn, revenue, NPS.
When you start defining SLAs and SLOs for data quality and data observability, alongside traditional uptime, you know your organization is treating data as a first-class product. That’s the foundation for sustainable model monitoring and a resilient ai project lifecycle.
How Buzzi.ai Builds Data-Engineering-First AI Systems
All of this can sound abstract until you have to implement it in a specific organization, with real legacy systems and political constraints. This is where a partner whose core competency is ai development services with strong data engineering can change the slope of your curve. At Buzzi.ai, we deliberately lead with data reality, not model fantasy.
Discovery: Start with Data Reality, Not Model Fantasy
Our engagements typically begin with structured AI discovery, not a model demo. We inventory key data sources, map data flows, and assess readiness across governance, lineage, and observability. We look for the gaps that would quietly kill a promising AI initiative six months in.
In some cases, that means telling a client, “You’re not ready for a production chatbot yet; you first need a reliable knowledge base and feedback loop.” This ai readiness assessment mindset is built into our AI Discovery service, which is explicitly designed around the realities of data engineering for AI projects and the end-to-end ai project lifecycle.
We’ve seen situations where, after discovery, the highest ROI work was cleaning up reference data and event schemas rather than adding another model. That’s the kind of call you can only make if you start with data.
Architect and Implement Robust AI Data Foundations
Once we understand your landscape, we design and build the data foundations tailored to your use cases: pipelines, feature stores, observability, and governance. That often includes integrating with existing warehouses or lakes, layering in workflow and process automation, and connecting AI outputs to downstream systems.
For example, in an intelligent document processing or support ticket routing scenario, we don’t just build models. We implement ingestion, extraction, predictive analytics development, and decisioning loops that route tickets or documents automatically, with clear audit trails. The goal is a pragmatic, cloud-agnostic enterprise AI implementation that respects your current stack.
Because we view data engineering as the primary product, we also design for reuse: the same pipelines that power one AI use case are available for the next.
Own the Lifecycle: From Pilot to Stable Production
Finally, we commit to production success. That means building and operating monitoring, retraining pipelines, and governance operations alongside model deployment. We think of this as combining data engineering for AI consulting services, enterprise AI solutions, and mlops services under one roof.
A typical engagement might involve a 6–12 week discovery and foundation phase to get your first use cases into stable pilot, followed by ongoing optimization and expansion. We don’t disappear after the demo; we stay to make sure your ai model deployment services actually hold up in production.
If you’re evaluating AI initiatives today, the most valuable step may be a data-engineering-first review of one current or planned project. That’s where we can help.
Conclusion: Fund the 80% That Actually Ships
Most AI narratives focus on models, but in production, it’s data engineering that determines success. The organizations that win are quietly reallocating 70–80% of their AI budgets and headcount toward pipelines, quality, and governance rather than chasing the latest algorithm.
Robust data architecture and observability are not add-ons; they’re preconditions for reliable AI systems. A phased, data-engineering-first roadmap can both rescue struggling projects and de-risk new ones by turning fragile experiments into durable products.
If you take one step after reading this, make it this: pick a single AI initiative and audit it through a data engineering for AI lens. Ask where the real risk lives, how you’re measuring data health, and whether your architecture can handle change. When you’re ready to turn that audit into a concrete plan, we’d be happy to explore a structured discovery and architecture engagement—starting with the data foundations your AI actually needs. You can learn more about our approach through our AI Discovery service.
FAQ
Why do most AI projects fail at the data engineering stage rather than at the model?
Most AI projects stumble because the data feeding the model is inconsistent, incomplete, or poorly governed. Models are surprisingly robust when their inputs are stable; they are brittle when schemas drift and quality isn’t monitored. Without strong data engineering for AI—pipelines, validation, observability—projects die long before model performance becomes the bottleneck.
What does data engineering for AI include beyond traditional ETL?
Beyond ETL, data engineering for AI spans end-to-end pipelines, feature engineering, feature stores, governance, lineage, and data observability. It also includes AI-specific testing like drift detection, label integrity checks, and integration with mlops workflows. In short, it’s the full lifecycle of turning raw data into reliable, reusable model inputs in both training and production.
How should we split our AI budget between data engineering and modeling work?
A practical starting point is allocating 70–80% of your AI budget to data engineering and platform work, and 20–30% to modeling, UX, and integration. This reflects where time and risk actually live in most AI initiatives. As your data platform matures, you may shift slightly toward models, but underfunding data early almost always leads to higher downstream costs.
What is a good data engineer to data scientist ratio for AI teams?
For complex enterprise AI, a healthy ratio is typically around 1.5–2 data engineers per data scientist or ML engineer. That mix ensures there is enough capacity to build and maintain pipelines, validation, and observability while still advancing modeling work. Teams heavily skewed toward modeling roles without sufficient data engineering support tend to get stuck in fire drills and rework.
How is data engineering for AI different from data engineering for BI and analytics?
BI-focused data engineering optimizes for aggregated, historical reporting with relatively relaxed freshness and edge-case requirements. Data engineering for AI must handle lower latency, finer granularity, labels, and stricter behavior under drift and missing data. AI systems are also more sensitive to subtle data changes, so you need stronger contracts, monitoring, and governance than a typical dashboard stack.
What data architecture patterns work best for enterprise-scale AI systems?
Most enterprises find success with a modern lakehouse architecture that combines the flexibility of data lakes with the performance and governance of warehouses. On top of that, you layer feature stores, orchestration, and mlops tooling for model deployment and monitoring. The specifics vary, but scalable data architecture, clear lineage, and well-defined online/offline separation are universal.
How can we measure whether our data engineering is "good enough" for production AI?
Define and track operational metrics such as data freshness, coverage, pipeline failure rates, validation error rates, and drift indicators. Correlate these with model performance and business KPIs over time to understand their impact. When you have clear SLAs around data quality and observability, and incidents are rare and quickly diagnosable, your data engineering is approaching “good enough.”
What are the most common data engineering mistakes that undermine AI projects?
Common pitfalls include relying on manual, undocumented pipelines, skipping data validation, and treating feature engineering as ad-hoc notebook work. Many teams also underestimate the need for observability and lineage, making debugging painful. Finally, failing to plan for schema evolution and governance guarantees that seemingly small changes will break production AI systems at the worst possible time.
How should we phase data engineering work across the AI project lifecycle?
Early phases should focus on assessment, quick wins, and building core pipelines for one or two high-value use cases. Mid phases emphasize hardening: observability, governance, feature stores, and standard patterns. Later phases scale reuse across multiple AI products, turning data engineering investments into a shared platform rather than isolated projects.
How can a partner like Buzzi.ai help implement a data-engineering-first AI strategy?
A partner like Buzzi.ai can start with an AI Discovery engagement to map your current data landscape and identify the highest-leverage improvements. From there, we design and implement robust pipelines, feature stores, and mlops foundations aligned with your use cases. Because we specialize in data engineering for AI consulting services, we help you avoid common pitfalls and accelerate from pilot to stable production. Learn more at our AI Discovery page.


