AI Software Cost Iceberg: Model the Real TCO Before You Build
Rethink AI software cost as lifecycle TCO, not build price. Learn how to model inference, monitoring, retraining, and maintenance costs before you commit.

The AI system you can afford to build this quarter may be completely unaffordable to run next year—and most budgets don’t find that out until it’s too late. When leaders talk about AI software cost, they usually mean the proposal in front of them: a build quote, some hourly rates, maybe a license line.
But for any successful AI deployment, that build quote is just the visible tip of a much larger iceberg. The real AI software total cost of ownership is dominated by what happens after launch: inference, infrastructure, monitoring, retraining, data pipelines, governance, and ongoing maintenance. In other words, the question isn’t "How much does it cost to build this?"—it’s "What is the real cost of AI software after deployment over the next 3–5 years?"
In this article, we’ll walk through a pragmatic way to model those AI operational costs in a spreadsheet your CFO will actually trust. We’ll break down the cost stack, show how to build an AI software cost calculator for inference and monitoring, and then connect architecture choices (SaaS API vs self-hosted vs hybrid) directly to total cost of ownership. If you’re a C-level leader, product owner, or technical decision-maker under pressure to justify AI ROI and avoid overruns, this is designed for you.
At Buzzi.ai, we’ve learned that the most valuable work often happens before anyone writes a line of code: modeling lifecycle AI total cost of ownership, exploring architecture tradeoffs, and designing for sustainable operations. We’ll show you how we think about it, so you can apply the same discipline to your own roadmap—whether you work with us or not.
The Real AI Software Cost: Why Run Beats Build
If you look at most vendors’ proposals, AI software pricing sounds straightforward: a fixed build fee, maybe a small retainer, and some optimistic assumptions about cloud usage. On paper, development looks like the big decision. In reality, development is often the smallest, loudest line item in a multi-year budget where operations quietly dominate.
Across many AI deployments, 60–80% of lifecycle spend shows up after launch. McKinsey has warned that a large share of AI initiatives fail to meet expectations, often because ongoing costs and complexity were underestimated. Boards love capex—they can approve a neat build budget—but opex grows in the background for 18–24 months until someone asks why the cloud bill is bigger than the original project.
Why development cost is the smallest, loudest line item
Imagine you’re building an AI support chatbot for a mid-sized SaaS business. A vendor quotes $300K in AI development cost: requirements, data work, model integration, UI, and initial deployment. It’s a serious investment, but finite and obvious—exactly the kind of number that fits in a board slide.
Now fast-forward. The bot launches, adoption grows, and you start to see the real AI operational costs: inference charges, infrastructure, monitoring tools, retraining, and on-call engineering. The result is a very different AI total cost of ownership profile.
Consider a simplified 3-year view:
- Year 0–1: Build and pilot – $300K build, $120K run (inference + infra + monitoring + support)
- Year 2: Scaling usage – $0 build, $400K run
- Year 3: Mature adoption – $0 build, $520K run
In this very plausible scenario, you spend $300K to build and over $1M to run the system over three years. Yet the whole conversation internally probably focused on "Is $300K a fair build price?" That’s the disconnect leaders need to close when talking about AI software cost.
The AI cost iceberg: visible build, hidden operations
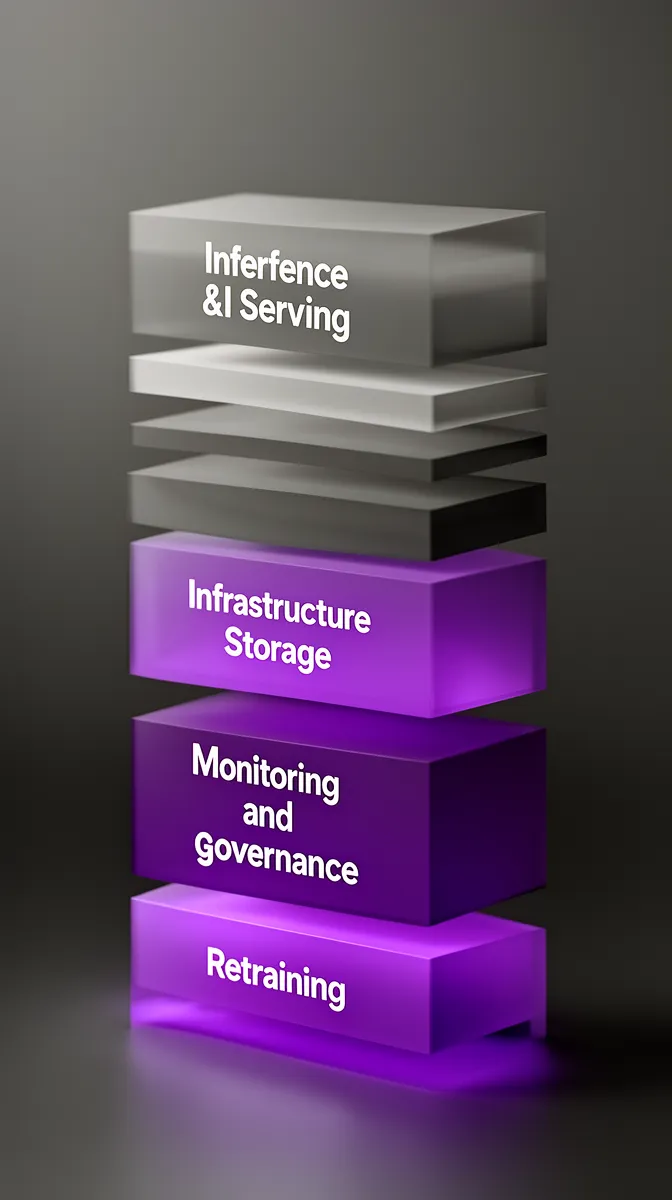
The reality of AI maintenance and monitoring cost breakdown looks a lot more like an iceberg. Above the waterline, everyone sees the build phase: design, development, initial training, integration. Below the surface are the ongoing layers that define what is the real cost of AI software after deployment:
- Inference and serving: every prediction, API call, and token processed
- AI infrastructure costs: GPUs/CPUs, autoscaling clusters, load balancers, model hosting
- Storage: training data, logs, model artifacts, embeddings, backups
- Monitoring and observability: tools, dashboards, alerts, and the humans watching them
- Retraining and evaluation: data labeling, training compute, A/B tests, rollout/rollback
- Security and compliance: audits, governance processes, documentation, risk management
Take a vision model that classifies product images. In year one, you might spend $150K on development and $50K on early operations. By year two and three, as catalogs grow and more teams integrate the model, AI inference costs and storage dominate: e.g., $250K/year on GPUs and storage, plus another $100K/year on retraining, monitoring, and maintenance. The iceberg has flipped: the submerged mass is where most of your money goes.
Why AI operational costs often exceed build in 18–24 months
The main reason AI software total cost of ownership is dominated by run, not build, is usage-based pricing. Whether you pay per token, per 1,000 predictions, or per API call, the unit price may look tiny—but it multiplies with traffic growth. What felt like a rounding error in your pilot becomes a material P&L line when the feature succeeds.
Worse, higher performance often implies higher unit costs. To improve accuracy or latency, you upgrade to a larger model, increase context windows, or move to premium GPUs. That pushes up AI inference costs and infra spend just as adoption accelerates. Meanwhile, data labeling, evaluation runs, and governance overhead turn into recurring human and tooling costs.
If you plotted cumulative build vs run spend over 24 months for a growing AI feature, the curves typically cross around month 12–18. By month 24, operations have usually doubled or tripled the initial build cost. That’s why any credible conversation about "how much does it cost to run AI software in production" has to be framed as lifecycle AI budget planning, not a one-time project quote.

Map the AI Cost Stack: From Request to Retraining
To get a handle on AI operational costs, you need to think in layers—what happens from the moment a user makes a request to the moment you retrain your models. This is where ai inference cost modeling for businesses meets the messy reality of GPUs, logs, and governance processes.
By mapping each layer explicitly, you turn a fuzzy "AI spend" line into a set of controllable levers. That’s the foundation for lifecycle cost modeling and, ultimately, cost optimization.
Cost layer 1: Inference and serving
Inference is where the rubber meets the road—and where a lot of surprise spend hides. At its simplest, AI inference costs are just the cost per prediction: per 1,000 tokens, per request, or per batch, depending on your architecture. The drivers are straightforward: model size, context window, traffic volume, latency SLOs, and GPU usage vs CPU.
With managed APIs like OpenAI, you pay based on API token pricing. For example, suppose you handle 1M requests/month, each averaging 800 tokens (prompt + completion), at $0.002 per 1K tokens. Your monthly inference bill is 1,000,000 × 800 ÷ 1,000 × $0.002 = $1,600. That sounds trivial—until you scale to 50M requests and richer prompts, where the same pattern can yield six-figure annual spend. You can see current pricing patterns on OpenAI’s pricing page.
If you self-host an open-source model, inference looks different. Instead of paying per token, you pay for GPUs and serving infrastructure: say 2 A10G GPUs at $1.50/hour each, running 24/7, plus surrounding CPUs and storage. That’s roughly $2,200/month in GPU time alone, before any overhead. The net cost per prediction depends on how much traffic you can squeeze through that capacity without violating latency SLAs—a classic latency vs cost tradeoff.
Cost layer 2: Infrastructure, storage, and networking
Underneath inference sit your core AI infrastructure costs. Cloud compute is usually the main component: always-on vs autoscaling clusters, reserved vs on-demand instances, and which GPU generations you use. Cloud compute costs can vary by 2–3x depending on instance choice and commitment level.
Then there’s storage: training data, logs, model checkpoints, embeddings, backups. Over a few years, even "cheap" object storage adds up, especially if you keep multiple historical versions for compliance or rollback. Networking and egress charges—particularly if you run multi-cloud, cross-region, or have heavy data-lake access—can quietly add 10–20% on top of your infra spend. You can see the flavor of these costs in pricing docs like AWS EC2 GPU pricing and GCP storage tiers.
A mid-size production deployment might run something like: 2 GPU instances at $1.50/hour each (~$2,200/month), supporting CPU instances at $800/month, storage at $300/month, and networking at $200/month. That’s $3,500/month in base infra before any burst capacity or regional redundancy. As you start scaling AI workloads, those numbers climb quickly.
Cost layer 3: Monitoring, observability, and governance
Most non-AI systems have monitoring; AI systems need more. AI monitoring covers model performance monitoring (accuracy, precision/recall, hallucination rates), latency, error rates, and data drift detection. You need dashboards, alerts, and workflows for investigating issues—especially if your models touch revenue or regulated decisions.
You can buy third-party tools or build on your existing observability stack, but either way you pay twice: in tools and in people. A typical arrangement might be a monitoring subscription at $2K–$5K/month plus roughly 0.25–0.5 FTE of a data scientist or MLOps engineer to review metrics, triage issues, and run experiments. Then add governance overhead: audits, compliance checks, and documentation aligned to frameworks like the NIST AI Risk Management Framework.
These are exactly the layers most "quick" budgets skip. Yet any honest AI maintenance and monitoring cost breakdown will show that underestimating monitoring and governance is one of the fastest paths to budget overruns—or to sweeping problems under the rug until regulators or customers notice.
Cost layer 4: Retraining, evaluation, and maintenance
Models don’t stay good by themselves. You’ll retrain when data drifts, when the product changes, when you enter new markets, or when regulations shift. Each retraining cycle has its own cost structure: data labeling, feature engineering, training compute, evaluation runs, and rollout/rollback engineering.
Suppose you decide on a quarterly retraining schedule for a key model. Each cycle costs $30K in combined labeling, MLOps effort, and training compute. That’s $120K/year, or $10K/month if you annualize it as a budget line. Move from quarterly to annual retraining, and you cut that in half—but perhaps at the cost of degraded performance. These are the kinds of tradeoffs that should be visible in your maintenance budget and not left to ad-hoc firefighting.
On top of retraining, you have routine ai model training experiments for improvements, plus ongoing maintenance of pipelines, APIs, SDK updates, security patches, and dependency updates. In a serious production deployment, those are not side projects; they are core parts of your production deployment TCO profile.
How to Calculate AI Inference and Operational Costs
Once you’ve mapped the layers, the next step is turning them into numbers. You don’t need a PhD to build an effective AI software cost calculator—you need clear assumptions, a few simple formulas, and the discipline to treat AI inference cost modeling for businesses as a first-class budgeting exercise.
We’ll walk through a practical four-step approach: define usage assumptions, build inference formulas, add monitoring and support overhead, and incorporate retraining and evaluation. This is the best way to estimate AI operational costs before you ship, not after.
Step 1: Define usage assumptions your CFO will accept
The first step in credible AI budget planning isn’t a model choice—it’s agreeing on demand. Translate product assumptions into finance-friendly inputs: daily active users (DAU), requests per user per day, and tokens per request. These are the knobs that drive AI software cost more than any line item in a proposal.
A good pattern is to define best case, likely, and worst-case scenarios over 36 months. For a customer support AI agent, you might draft a simple table:
- Month 1: 1,000 DAU, 3 requests/user/day, 500 tokens/request
- Month 12: 10,000 DAU, 4 requests/user/day, 700 tokens/request
- Month 36: 30,000 DAU, 5 requests/user/day, 900 tokens/request (likely)
Replicate that for lower and higher growth scenarios. Document every assumption explicitly so you can revisit them as reality emerges. You’re effectively building an AI project budget template including operational costs where usage is a shared truth, not a hand-wavy footnote.
Step 2: Build a simple inference cost formula
For managed APIs, your core formula is straightforward. If you know requests per month, tokens per request, and price per 1K tokens, then:
Monthly inference cost (API) = Requests × Tokens per request ÷ 1,000 × Price per 1K tokens
For example, 1M requests/month × 800 tokens/request ÷ 1,000 × $0.002 = $1,600/month. If you grow to 20M requests and 1,200 tokens, the same formula yields $48,000/month. That’s the moment when leaders ask, "How much does it cost to run AI software in production if we keep growing like this?" A good spreadsheet makes the answer trivial.
For self-hosted, think in capacity terms:
Monthly inference cost (self-hosted) = (GPU hours × GPU hourly rate) + CPU/infra overhead + storage / Requests
If you run 4 GPUs at $1.50/hour, 24/7, that’s ~2,880 GPU hours/month, or $4,320/month. Add $1,500/month in CPU, storage, and networking. If you process 20M requests, your base infra cost per prediction is roughly $0.00029—then add your overhead for MLOps staff. Converting both approaches into cost per prediction and cost per active user lets you compare apples to apples.
Step 3: Add monitoring, observability, and support overhead
Inference is only part of the story. A common rule of thumb is that monitoring, observability, and support will add 10–20% of your inference spend, depending on complexity. If your base inference bill is $40K/month, expect another $4K–$8K in tools and a meaningful slice of FTE time to manage them.
Concretely, you might add a monitoring stack subscription ($3K/month) plus 0.5 FTE of an MLOps engineer and 0.25 FTE of a data scientist. At fully loaded rates, that might be another $12K–$18K/month. A serious AI maintenance and monitoring cost breakdown will treat this as part of core AI operational costs, not "nice to have" work squeezed into spare cycles. The more models you run, the more you need real mlops capacity.
Step 4: Incorporate retraining and periodic re-evaluation
Finally, fold model retraining into your model. Different use cases justify different frequencies: pricing or fraud models might be retrained weekly or monthly; support intent models might be quarterly; recommendation engines might be somewhere in between. The key is to decide an initial retraining schedule and budget for it upfront.
Say you plan one major retrain per year at $120K (data work, compute, engineering) plus two minor refreshes at $30K each. That’s $180K/year in retraining and evaluation. Spread across 12 months and three years, you get a clean $15K/month budget line for retraining. Adding this to your inference, infra, and monitoring lines gives you a concrete view of lifecycle AI total cost of ownership and supports better lifecycle cost modeling.

Architecture Choices and Their Impact on AI TCO
Once you understand the levers, architecture becomes a financial decision as much as a technical one. Three broad patterns dominate enterprise AI adoption: managed SaaS APIs, self-hosted open-source models, and hybrid architectures. Each has a distinct AI software total cost of ownership profile and different AI software cost curves over time.
The right answer for a pilot is often the wrong answer for a scaled product. Modeling TCO across options in one spreadsheet is how you avoid getting locked into an expensive path just because it was fast to start.
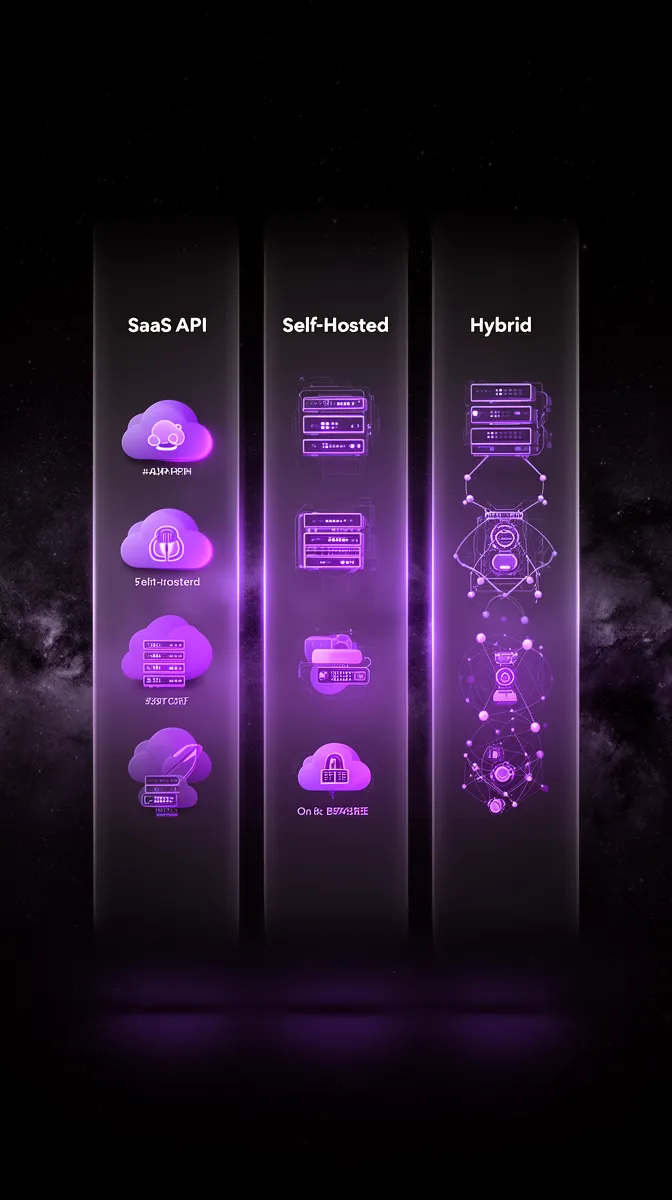
Option 1: Managed SaaS APIs (fast to start, pay per use)
Managed SaaS APIs are the on-ramp most teams start with. You get low upfront cost, almost no infra or mlops to manage, and rapid iteration. Your AI software pricing is almost entirely usage-based pricing: per token, per request, maybe some tiered discounts.
The downside is that unit cost is tied to vendor pricing and can be high at scale. You also face practical limits: rate limits, softer control over performance, and data residency or compliance concerns. For many teams, this is ideal for pilots, low/medium-volume features, or non-sensitive workloads—but dangerous if you never revisit the choice as volumes grow.
In TCO terms, a pilot might look like $50K build + $2K/month in API fees. If you stay on the same architecture at 100x traffic, you might find yourself at $400K–$600K/year in API spend alone. A responsible AI software cost calculator makes that curve visible from day one.
Option 2: Self-hosted and open-source models (control vs complexity)
Self-hosting gives you control: over data, models, latency, and to some extent unit cost. At high volume, you can often beat vendor pricing on a per-prediction basis, especially if you invest in model distillation, caching, and smart capacity planning. But you’re trading vendor margin for your own AI infrastructure costs and headcount.
The costs here include cloud compute costs for GPUs/CPUs, model hosting infrastructure, security and compliance responsibility, and a dedicated mlops team. You might save 40% on unit inference cost compared to a SaaS API, but only if you have 2–3 FTEs to manage the stack and enough volume to amortize infra. For some organizations, especially those with strong SRE/MLOps cultures, this is a natural fit for stable, high-volume workloads.
Option 3: Hybrid architectures (optimize by workload)
Hybrid architectures mix both worlds. You keep some workloads on managed APIs—often the complex, low-volume edge cases where premium models shine—and run the bulk of traffic on cheaper, self-hosted or fine-tuned open-source models. This is often the best path to ai cost optimization once you’re past the pilot stage.
Consider a customer support bot with 90% FAQ-style queries and 10% complex cases. You might route FAQs to a smaller in-house model with low serving infrastructure cost and send edge cases to a SaaS LLM. You get lower average cost per prediction, better latency for common queries, and a safety valve for difficult ones. The tradeoff is complexity: two stacks to govern, more careful latency vs cost tradeoff management, and more moving parts when scaling AI workloads.
How to compare TCO across architectures in one spreadsheet
The practical way to choose is to normalize options into a single TCO view. For each architecture, compute:
- Total 3-year spend (build + run) under the same demand scenarios
- Cost per 1,000 requests and cost per active user
- Required FTEs (MLOps, data science, SRE)
- Qualitative factors: latency, compliance risk, vendor lock-in
Then run sensitivity analysis: what happens if traffic grows 2x faster than expected, or if the vendor cuts prices 30%, or if GPUs get cheaper? This is where AI software cost calculator meets strategy. Case studies of model distillation and caching—like those shared by engineering teams at large tech companies in public distillation and optimization write-ups—show that architecture and optimization choices can halve or quarter long-run TCO.
Building a 3-Year AI Software TCO Model
At this point, we can combine the ingredients into a real 3-year AI software total cost of ownership model. Think of it as a financial twin of your AI roadmap: for every feature or model, you can see its cost evolution alongside its business value. This is the best way to estimate AI operational costs before you greenlight major investments.
The basic structure is simple: define scope and KPIs, translate technical metrics into finance-ready lines, plan for cost evolution, and avoid common budgeting mistakes. Once you’ve done this once, it becomes a reusable template for future initiatives.
Define scope: product, use cases, and success metrics
Start by deciding what’s in scope. Are you modeling a single AI feature (like a support bot), a cluster of capabilities (personalization across your product), or an entire platform? Without a clear boundary, your AI total cost of ownership model will be vague and unhelpful.
Then tie costs to business KPIs: tickets deflected, revenue uplift, churn reduction, time saved for internal teams. If your AI initiative costs $3M over three years but frees $10M of support capacity, it’s a good trade. If it costs $500K and moves no meaningful metric, it isn’t. This is also where enterprise AI adoption becomes a business discussion, not just a technology one.
Turn technical metrics into finance-ready budget lines
Next, translate "requests per second" and "tokens per request" into line items your finance team recognizes. Group spending into categories like:
- Infrastructure: GPUs, CPUs, storage, networking (your core AI infrastructure costs)
- Licenses and APIs: LLM APIs, vector DB subscriptions, monitoring tools
- People: MLOps, data science, product, and support roles tied to AI operations
- Governance and compliance: audits, certifications, external reviews
A sample budget excerpt might show "LLM API spend", "GPU instances", "MLOps headcount", and "Monitoring tools" as distinct GL codes. This helps your finance team track AI software pricing over time and distinguish between build and run. It also integrates naturally with forecasting processes and, if you use services like Buzzi.ai’s predictive analytics and forecasting services, you can align cost and value projections in one place.
Over time, you can also move toward more uncertainty-honest AI project cost estimates by tracking actuals vs forecasts and refining your assumptions about usage and optimization potential.
Plan for cost evolution: growth, optimization, and decay
A static snapshot of year-one cost is almost useless. Your model should explicitly show how costs change with adoption and optimization. That means projecting usage growth, but also modeling optimization wins: better prompts, caching, model distillation, and hardware upgrades that reduce unit cost.
In a healthy TCO curve, you often see an initial spike (launch + early inefficiencies), followed by a dip as you optimize, then gradual growth as adoption scales. This is where ai cost optimization and lifecycle cost modeling pay off. You also want to model decay: when might you replace or decommission a service? If you expect to sunset an AI feature in year three, don’t model its costs as if they’re permanent.
Tech roadmaps, vendor price trends, and hardware cycles all feed into this. GPUs tend to get cheaper or more efficient; models improve. A 3-year ai software total cost of ownership model that assumes flat unit costs is conservative, but it may also understate the upside of optimization.
Common budgeting mistakes—and how to avoid them
Several mistakes repeat across organizations when they first tackle what is the real cost of AI software after deployment:
- Ignoring retraining entirely or treating it as a rare event
- Underestimating monitoring and governance needs
- Assuming flat usage instead of modeling growth scenarios
- Not modeling worst-case traffic or vendor price changes
The impact is predictable: surprise overruns, emergency procurement, or throttling successful features because the cloud bill is suddenly untenable. A simple sanity-check checklist helps: Do we have a clear AI project budget template including operational costs? Have we included retraining, monitoring, and support? Have we run upside and downside scenarios?
We’ve seen organizations launch promising AI features, then quietly shut them down six months later after a nasty billing surprise. With a proper AI software cost model, those decisions would have been visible and deliberate, not reactive.
Governing AI Operational Costs: KPIs and Vendor Selection
Modeling AI operational costs is step one; governing them over time is step two. That requires shared KPIs across finance and engineering, better vendor evaluation, and pricing structures that align incentives around AI software cost and optimization—not just deal size.
This is also where vendor choice and contract design start to matter as much as architecture. You want partners who think in terms of AI software total cost of ownership, not just build price.
KPIs finance and engineering should track together
Good KPIs make tradeoffs visible. Common metrics include:
- Cost per 1,000 predictions and cost per active user
- Infra spend as a percentage of AI-driven value (revenue uplift, cost savings)
- Model failure rates, latency SLO adherence, and incident frequency
On top of that, track early-warning indicators: month-over-month spend growth vs usage growth, API or GPU cost anomalies, and trends in unit cost. A shared KPI dashboard might show unit cost, latency, and accuracy trends next to total spend. This supports ai cost optimization, ai budget planning, and disciplined ai software pricing conversations in the same meeting.
How to compare vendors on lifecycle TCO, not build price
When you run RFPs or evaluate partners, insist on lifecycle views. Ask vendors to provide 3-year TCO projections under different demand scenarios, not just day-one build quotes. The question isn’t "Can you build this?"; it’s "How does this behave financially as we scale?"
Concrete questions to ask include: How do you model inference, monitoring, and model retraining? Who owns which costs post go-live? How do you support architecture changes (e.g., moving from SaaS API to hybrid) if usage crosses a threshold? A good AI software cost calculator from the vendor side is a strong signal that they understand AI software total cost of ownership and aren’t outsourcing risk to you.
What transparent, TCO-aligned pricing from vendors looks like
Transparent, TCO-aligned pricing has a few characteristics. It separates build and run clearly, exposes unit economics, and offers options tied to architecture and volume tiers. Instead of just a single quote, you might see three options: pilot on SaaS API, scaled hybrid, and full self-hosted—each with explicit 3-year cost curves.
Contracts can also embed shared-savings incentives: if optimizations reduce your run cost by X%, both you and the vendor benefit. That pushes everyone toward better ai cost optimization over time instead of quietly tolerating inefficient architectures. In a world where enterprise AI adoption is still early, these structures are a good test of whether vendors design for your long-term success or their next quarter’s revenue.
How Buzzi.ai designs and prices around full lifecycle costs
At Buzzi.ai, we start with workload modeling, not just feature wishlists. Our AI discovery and roadmap engagement explicitly includes 3-year TCO modeling and architecture tradeoff analysis before we quote a build. That’s how we make sure the AI you can afford to build is the AI you can afford to run.
We also design proposals that bake in monitoring, retraining, and maintenance planning as first-class components, whether we’re building AI chatbots, workflow automation, or custom AI agents. In one anonymized client project, we recommended a hybrid architecture instead of pure SaaS APIs; the result was a projected 40% reduction in 3-year TCO while maintaining performance. That’s the kind of lifecycle-aware design we think should be standard across ai strategy consulting and ai implementation services.
Conclusion: Turn AI Cost from Guesswork into a Model
The biggest lesson from the AI cost iceberg is simple: AI software cost is dominated by operations over 3–5 years. Inference, infrastructure, monitoring, and retraining almost always outweigh the build budget. If you ignore them, you’re not really talking about AI software total cost of ownership at all.
The good news is that you don’t need exotic tools to get this right. A straightforward, spreadsheet-ready TCO model—the kind we’ve outlined here—is the best way to estimate AI operational costs, compare architectures, and avoid nasty surprises. It also changes the conversation from "Can we afford to build this?" to "Is this the right way to build and run this for the next three years?"
That’s where Buzzi.ai can help. If you’d like to turn your current or planned AI initiative into a concrete 3-year TCO model—complete with architecture options, inference cost curves, and retraining plans—we offer a focused discovery engagement to do exactly that. You can learn more about our approach and services on our AI discovery page and start designing AI that’s financially sustainable from day one.
FAQ: AI Software Cost and Lifecycle TCO
What is the true cost of AI software beyond initial development?
The true cost of AI software extends far beyond initial development and deployment. Over 3–5 years, most spend shifts to inference (per prediction or token costs), infrastructure, monitoring, retraining, and governance. A realistic AI software total cost of ownership model will show that operations often account for 60–80% of lifetime cost.
Why do AI operational costs often exceed development costs within 18–24 months?
AI operational costs tend to exceed development as usage grows and usage-based pricing compounds. Each new user and each additional request incurs inference, storage, and networking charges, and more volume typically requires more monitoring, retraining, and MLOps support. By 18–24 months, successful features can easily double or triple the initial build cost in run expenses.
How can I calculate the cost of running AI inference in production?
To calculate inference cost, estimate monthly requests, average tokens or payload size, and unit pricing (per 1K tokens or per request). For managed APIs, multiply requests × tokens/request ÷ 1,000 × price per 1K tokens; for self-hosted, divide total GPU and infra cost by the number of predictions. Embedding this into an AI software cost calculator lets you explore different growth and architecture scenarios.
What factors drive AI inference costs like model size, traffic, and latency?
Key drivers of AI inference costs include model size (larger models use more compute), context window length, traffic volume (requests per second), and latency requirements. Strict latency targets often force you to run more or faster GPUs, raising GPU usage and serving infrastructure costs. Architecture choices—SaaS APIs vs self-hosted vs hybrid—also affect unit cost and scalability.
How do I estimate the monitoring and observability costs for AI systems?
A practical approach is to apply a rule of thumb—10–20% of your inference spend—for monitoring tools and observability. Then add fractional FTEs for MLOps, data science, and SRE roles that review metrics and manage incidents. Together, these lines form the core of your AI maintenance and monitoring cost breakdown and should be included in any serious TCO model.
How often should AI models be retrained, and how do I budget for retraining?
Retraining frequency depends on your use case: fast-changing domains like pricing or fraud may need weekly or monthly retrains, while support intent models might be refreshed quarterly or annually. To budget, estimate the full cost of each retrain—data labeling, engineering, training compute, evaluation—and multiply by expected frequency. Spreading the total over 12 months turns it into a predictable maintenance budget line.
What hidden infrastructure costs should I expect after deploying AI software?
Hidden infrastructure costs often include always-on GPU instances, backup and archival storage, cross-region networking and egress fees, and extra capacity for failover or traffic spikes. Over time, more models and features also mean more pipelines, logging, and security tooling. All of these should be captured under AI infrastructure costs in your TCO model, not treated as generic IT overhead.
How do SaaS APIs, self-hosted models, and hybrid architectures compare on TCO?
SaaS APIs offer low upfront cost and fast time-to-market but can become expensive at high volume due to usage-based pricing. Self-hosted models can deliver lower unit costs and more control but require significant MLOps capability and infra spend. Hybrid architectures often strike the best balance, using premium APIs for complex edge cases and cheaper in-house models for bulk traffic.
How can I build a simple 3-year AI software total cost of ownership model?
Start by defining scope and usage assumptions, then layer in inference, infrastructure, monitoring, and retraining costs for each year. Convert technical metrics like tokens and requests into financial lines that finance understands, and model multiple demand scenarios. If you want help, Buzzi.ai’s AI discovery and roadmap engagement is designed to produce exactly this kind of 3-year TCO model.
How does Buzzi.ai’s approach help reduce AI software cost over the full lifecycle?
Buzzi.ai focuses on lifecycle TCO from day one, modeling how different architectures and vendors affect long-term AI software cost. We design solutions with monitoring, retraining, and governance baked in, so there are fewer surprises in year two or three. In many cases, this leads us to recommend hybrid or alternative architectures that materially reduce 3-year TCO while maintaining or improving business impact.


