AI API Integration Services That Don’t Break in Production
Most API playbooks fail with AI. Learn AI-specific API integration services, patterns, and safeguards that keep LLM features reliable in production.
If you integrate AI APIs the same way you integrate Stripe or Twilio, your product will look fine in demos and mysteriously fall apart in production.
Traditional integrations assume deterministic REST APIs: you send a request, you get a predictable response, and if something breaks, it breaks the same way every time. With modern AI API integration—especially LLM APIs—you’re dealing with probabilistic systems whose behavior shifts under your feet.
The result is familiar: AI features that pass QA, delight in a sales demo, and then randomly misbehave in production. You see intermittent failures, long-tail bugs that no one can reproduce, latency spikes, weird edge-case behavior, and outputs that are technically “successful” but wrong or unsafe. This is where most generic ai api integration services quietly hit their limits.
To make AI features production-grade, you need a different mental model: validation layers, fallbacks, latency-aware design, and deep observability around every llm api call. In this article we’ll unpack why the old patterns fail, look at concrete AI-specific integration patterns, and map when to bring in ai api integration services for enterprises instead of scaling DIY experiments.
At Buzzi.ai, we focus on these AI-aware integrations for SaaS and enterprise teams—wrapping LLMs, hybrid AI and traditional APIs, and async orchestration in guardrails that survive real-world chaos. Let’s start with why AI APIs break the mental model you’re used to.
Why AI API Integration Is Not Just Another REST Project
Deterministic vs probabilistic: why AI breaks old assumptions
Most engineering teams have internalized how deterministic REST APIs behave. You call a payments API with a well-formed request, you either get back a valid JSON object or a clear error. The contract is stable, schema-validated, and repeatable: same input, same output.
With LLM APIs and ml model inference, you’re no longer calling a deterministic function; you’re sampling from a probability distribution. The same prompt can produce different completions, quality varies between calls, and outputs can be subtly wrong, off-brand, or unsafe while still looking superficially “fine.” Classic test cases that pass once don’t guarantee ongoing correctness.
Contrast a payment capture endpoint with a chat completion endpoint. The payments API returns a fixed schema: status, amount, currency, transaction_id, error_code. In an LLM-based chat endpoint, you get a blob of natural language whose structure, tone, and factuality are all variable. That’s why generic ai api integration work—treating LLM calls like any other HTTP call—so often under-scopes the real problem.
Once you start chaining hybrid ai and traditional apis—say, call a search API, feed results to an LLM, then write to a database—the blast radius of that variability gets much bigger. Without explicit guardrails, you’re effectively wiring a stochastic system into deterministic infrastructure and hoping for the best.
New failure modes: hallucinations, safety blocks, and silent drift
In deterministic systems, failure modes are mostly explicit: network errors, HTTP 500s, validation errors. With LLM APIs you inherit a richer set of AI-specific error modes. Hallucinations, unsupported instructions, safety and policy blocks, model version changes, and vendor-side rate caps all show up in production.
The subtlety is that an HTTP 200 from an LLM endpoint does not mean “good result.” It only means “the model returned something.” You still need hallucination detection, content moderation filters, and application-level error handling to decide whether the result is acceptable—functionally, factually, and from a policy perspective. That’s one reason robust ai model monitoring is so central to AI-native systems.
Then there’s drift. Your integration may be stable, but the vendor silently upgrades their model, tweaks safety parameters, or changes training data. The distribution of outputs shifts while your code stays the same. Suddenly your customer support assistant becomes overly cautious and refuses benign queries because of a new policy rule, or your summarizer starts fabricating legal terms it never did before. Without proper observability, you only discover this via angry tickets.
Why “just call the model” integrations become brittle in production
The most common AI integration pattern we see starts simple: an engineer wires a front-end button to call an LLM endpoint directly from the backend (or worse, the browser), passes the prompt, and displays whatever text comes back. For an internal demo this looks magical. For production, it’s a time bomb.
Under real load, this direct openai api integration hits rate limits, latency spikes, and provider-side issues that naive retry logic can’t handle. Outputs vary, edge cases show up, and there’s no central place to enforce validation, monitor behavior, or manage prompts. Service-level objectives around latency and quality of service start slipping, and nobody can explain why because logs are thin and behavior is probabilistic.
One SaaS company we worked with rolled out an “AI assistant” this way. It passed QA, wowed sales, and then started causing P1 incidents: unbounded response times during peak load, inconsistent answers across tenants, and no clear way to reproduce or fix bugs. The lesson was clear: robust ai api integration services for enterprises must assume variability and wrap every LLM call in safety nets—latency controls, validation, and structured ai pipeline orchestration—instead of just “calling the model.”

Design Principles for Production-Grade AI API Integration
Once you accept that AI APIs behave differently, the question becomes: how do you design ai api integration services that can handle that variability without degrading user experience or blowing up reliability?
Assume variability, design for envelopes not points
With classic systems, we talk in single numbers: average latency, 99th percentile, fixed timeout. For AI APIs, it’s more useful to think in envelopes—ranges of acceptable latency, quality, and safety—and design your product around those distributions rather than point estimates.
For latency management, you might define an envelope like “200–1500ms for a chat response.” Inside 500ms, you show a snappy inline result. Between 500–1500ms, you show a loader and keep the user engaged. Beyond 1500ms, you trigger a timeout, degrade gracefully, or flip to an asynchronous pattern. Similarly, you define envelopes for quality: minimum confidence scores, maximum allowed hallucination risk, acceptable error rates calibrated to your service-level objectives.
Those envelopes drive concrete decisions: prompt design, streaming vs non-streaming, fallback mechanisms, and UX messaging when the envelope is exceeded. This is where ai api integration patterns for latency and errors move from theory into UI: the same LLM can be experienced either as “magical” or “unreliable” depending on how well the rest of your system is designed for its variability.
Separate orchestration from inference
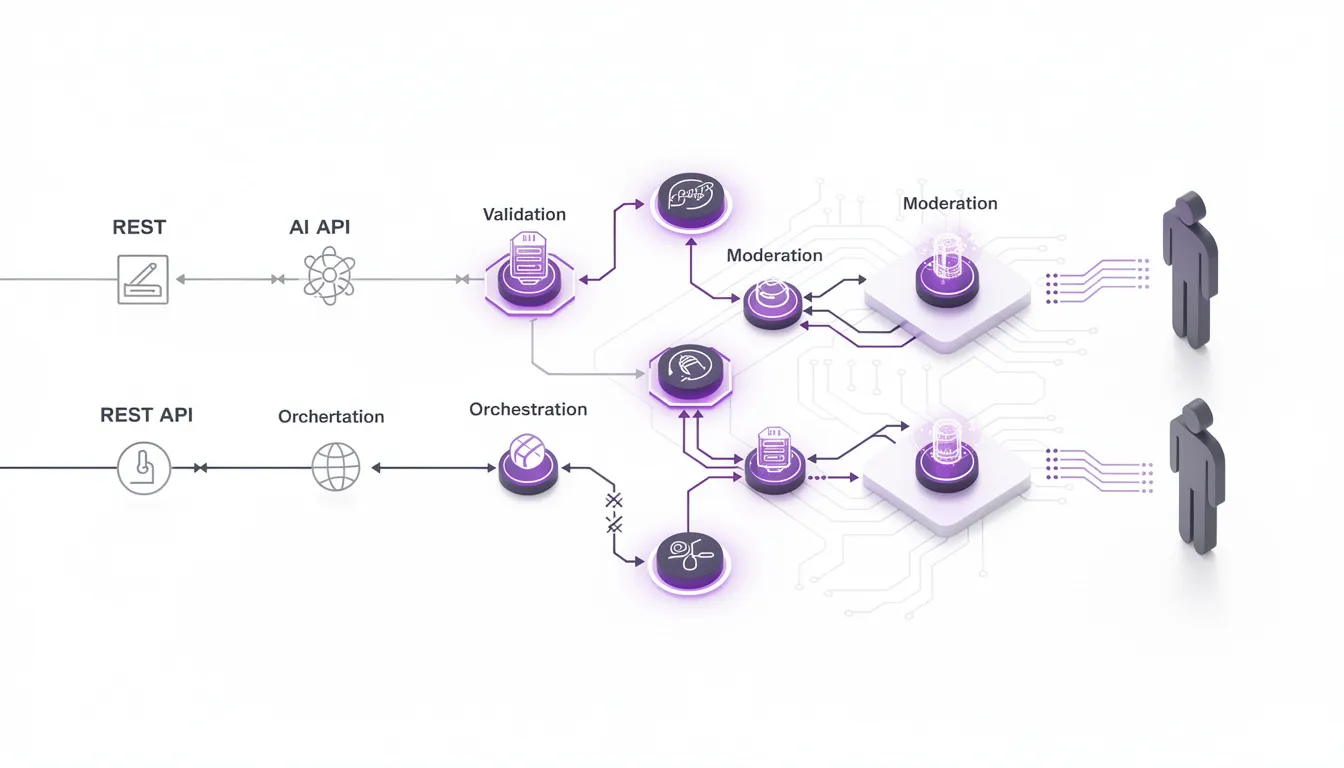
A second principle: never let your core business logic talk directly to LLM endpoints. Instead, introduce an AI orchestration layer that owns prompts, routing, retries, validation, and fallbacks. Treat AI providers as plugins behind that layer.
This orchestration can be implemented as dedicated ai microservices, a workflow engine, or a queue-based architecture—the form matters less than the separation. Your product code calls a clean, deterministic API (e.g., /summarize, /classify-ticket) and the orchestration layer decides which llm api to use, how to shape the prompt, and what to do if the call fails or returns a low-quality result. Logging, governance, and configuration live there, not spread across random feature modules.
Imagine a microservice that wraps all LLM calls for your platform. To the rest of the stack it exposes stable endpoints with clear contracts. Under the hood it manages ai pipeline orchestration: chaining retrieval, model calls, validation, and fallbacks. This architecture lets you swap models, add vendors, or experiment with new custom ai workflows without touching your main app.
Treat AI responses as untrusted until validated
The third principle is almost cultural: treat AI outputs like user input. Never assume they are correct, safe, or well-structured until you’ve checked. That means building first-class response validation and moderation into your integration patterns.
In practice, that can look like enforcing structured outputs (JSON schemas or function calling), running business-rule validation, and applying content moderation filters. If an LLM suggests updating an invoice, you might cross-check line items against existing customer records and pricing tables before applying the change. If validation fails, you retry with a refined prompt, return an error, or route to human review.
This mindset also helps with hallucination detection: when an AI claims something about your data or policies, your system should verify it against trusted sources instead of blindly trusting natural language. Combined with idempotent request design and careful error handling, this turns probabilistic outputs into safely consumable inputs for deterministic systems.
Core AI API Integration Patterns for Latency and Reliability
With the principles in place, we can get specific. This is where ai api integration patterns meet the day-to-day concerns of SRE and product teams: latency management, retry logic, circuit breakers, and cost control.
Adaptive timeouts, retries, and circuit breakers for AI APIs
Naive retry logic can turn a slow or flaky AI endpoint into an outage amplifier. If every request retries three times with a 30-second timeout, a brief slowdown at your provider can saturate threads, queues, and databases upstream. Instead, you need adaptive latency management and the classic circuit breaker pattern, tuned for AI workloads.
Adaptive timeouts adjust based on model type, request size, and user context. A small chat completion for an inline suggestion might time out in 800ms, while a large summarization job gets more slack. When error rates or latency exceed thresholds, the circuit breaker opens: your orchestration layer stops hammering the AI provider, immediately returns a fallback, and logs the incident for investigation. Combined with idempotent requests on downstream writes, this prevents cascading failures.
These patterns are well-understood in SRE literature—for example, in Google’s SRE best practices on circuit breakers and tail latencies—but most teams forget to apply them to AI calls because they’re “just another HTTP request.” Treat them as high-variance, high-cost dependencies, and design graceful error handling accordingly.
Synchronous vs asynchronous AI pipelines
Not every AI feature belongs in the synchronous request/response path. A huge class of use cases—long document analysis, bulk classification, deep analytics—are better served via asynchronous processing with a queue-based architecture and worker pools.
Use synchronous calls when the interaction is conversational or the computation is small: autocomplete, inline rewrite, short Q&A. For heavier tasks, send a job to a queue, return a job ID, and let workers process using your preferred ai pipeline orchestration. Users get progress updates via websockets, polling, or webhooks when results are ready.
Many large SaaS platforms describe this pattern in their engineering blogs: queue jobs, shard them across workers, and use observability dashboards to track throughput and latency. This is where ai api integration services for enterprises often step in, standardizing the async pipeline across multiple products instead of letting every team invent its own.
Fallback mechanisms: semantic downgrades, cached answers, and human-in-loop
When AI calls fail—or when outputs are low quality—you need smart fallback mechanisms so your product doesn’t grind to a halt. These fallbacks can be semantic (simpler answers), architectural (different systems), or human.
Semantic fallbacks might return a shorter summary, a template-based response, or the last known good answer when a full reasoning chain times out. At the infrastructure level, you can cache frequent AI responses and fall back to deterministic services like search or rules engines when the model is unavailable. For high-risk flows, you route to a human agent instead of forcing the AI to answer at all costs.
Consider an AI support assistant. Under normal operation it generates rich, personalized replies. If its confidence score is low or a safety policy triggers, it can degrade to FAQ search or surface suggested responses to a human agent. This keeps your quality of service and service-level objectives intact without pretending the AI is infallible—exactly the kind of custom ai workflows modern teams need.
Cost and rate-limit aware integration patterns
AI API usage is metered, and it’s easy to build delightful features that are financially unsustainable. The same goes for rate limits: naive designs can hit provider caps long before feature adoption plateaus. Cost and rate limiting need to be first-class design concerns, not afterthoughts.
Common strategies include batching related requests, caching repeated prompts and responses, and prioritizing high-value use cases over speculative features. You can also impose per-tenant quotas and build graceful degradation paths when rate-limit errors hit—return cached or partial results instead of hard failures. Product and finance teams should align on budgets and SLOs around “cost per successful AI interaction.”
One product we saw initially generated suggestions on every keystroke in a text box. It felt magical but exploded usage and cost. By moving to batched suggestions—triggering only on pause or explicit request—they maintained user experience while bringing spend under control. This is exactly the kind of design a managed ai api integration service provider will push you toward early, before numbers get scary.
For deeper dives into circuit breakers, retries, and observability patterns, the Google SRE book and related materials offer solid foundations that translate well into AI-heavy environments.
And if you need help operationalizing these patterns end to end, Buzzi.ai provides AI agent development and orchestration services that bundle latency, fallback, and reliability controls into reusable components.
Validation, Guardrails, and Governance for AI API Outputs
Even with solid latency and retry patterns, you’re not safe until you control what actually reaches your users and systems. This is where response validation, hallucination detection, and governance move from theoretical worries to concrete engineering.
Multi-layer validation: schema, constraints, and semantic checks
Robust validation happens in layers. First, schema validation: does the AI output conform to the expected structure and types? Second, business-rule constraints: do fields obey rules like max discounts, valid states, or cross-field consistency? Third, semantic checks: does this make sense given the context?
You can enforce schema via JSON schemas or typed function-calling; constraints via code that cross-references your source-of-truth databases; semantics via additional AI-powered checks or deterministic heuristics. In a pricing tool, if the AI suggests a 60% discount where the max allowed is 20%, business-rule validation catches it and either clamps the value, retries with stronger instructions, or routes for human approval.
Failures at any layer should trigger clear error handling paths in your ai pipeline orchestration: adjust the prompt, downgrade the response, or log and fall back. Done right, these patterns turn probabilistic AI into something your deterministic stack can trust.
Detecting and mitigating hallucinations and unsafe content
Hallucinations are not a bug in LLMs; they’re a consequence of how they work. The question is not whether they happen, but how you detect and contain them. Techniques for hallucination detection include grounding answers against enterprise data, checking for citations, and running a separate verifier model that scores factuality.
Content moderation filters are equally important: scanning outputs for toxicity, PII, or policy violations before they reach users. Many providers offer built-in moderation endpoints, but enterprises often combine those with custom filters tuned to their own risk profiles. Unsafe or low-grounding outputs should never quietly slip through; they should trigger fallbacks or human-in-the-loop review.
The research community and industry blogs are full of work on hallucinations and mitigation strategies; they all agree on one thing: you need continuous evaluation, not one-off tests. Ai model monitoring that tracks hallucination rates and unsafe outputs over time is a core part of responsible enterprise ai integration, not an optional add-on.
Observability and logging that respect privacy and compliance
Because AI behavior is probabilistic, logs and metrics matter even more than in traditional systems. You want to log prompts, outputs (or samples), model versions, latency, token counts, and validation outcomes. This gives you the raw material for debugging, A/B testing prompts, and tuning ai api integration patterns.
At the same time, privacy, security, and compliance requirements are non-negotiable. That means masking or hashing PII, encrypting logs at rest and in transit, and following strict retention policies. It also means understanding your vendors’ data-processing policies and how they affect your risk posture in ai api integration services for enterprises.
Good observability doesn’t just show charts; it encodes governance: who can see which logs, how access is audited, and how incidents get triaged. In regulated domains, this ties directly into auditability requirements under frameworks like the NIST AI Risk Management Framework or the upcoming EU AI Act.
Policy-aware integration: embedding rules into the orchestration layer
Finally, governance has to be executable. It’s not enough to have a PDF that says “never send PHI to non-HIPAA-compliant vendors.” You need your orchestration layer to enforce that rule automatically, based on data classification and geography.
Policy engines or configuration-driven routers can encode these decisions: EU user + sensitive data → on-prem or EU-hosted model; US user + non-sensitive data → cloud llm api. This turns “ai governance consulting recommendations” into hard constraints in your runtime, rather than hope and documentation.
At Buzzi.ai, we bake this into our enterprise ai integration work: governance and ai security consulting are part of the orchestration design, not a separate checklist at the end. The goal is an integration layer that knows which models can see which data under which conditions—and can prove it when auditors ask.
Architectures for Blending AI APIs with Existing Systems
Very few companies are building greenfield AI systems. More often, you’re integrating AI into a mature stack of microservices, search, rules engines, and human workflows. The question is how to integrate ai apis into existing applications without destabilizing what already works.
Wrapping AI in deterministic microservices
One powerful pattern is to hide AI variability behind deterministic microservices. Instead of letting every service call LLM APIs directly, you create internal ai microservices with clear contracts. The AI complexity lives inside; the outside world sees stable behavior.
For example, expose a /classify-ticket endpoint that always returns an enum (e.g., BILLING, TECHNICAL, ACCOUNT) and a confidence score. Internally, the service might combine search, heuristics, and one or more models. To other teams, it’s just another ai api integration they can consume with strong service-level objectives and monitoring.
This pattern simplifies enterprise ai integration: most engineers don’t need to learn LLM quirks or prompt engineering. They think in terms of business contracts while a smaller expert group (or a partner providing ai api integration services for enterprises) curates the AI internals.
Hybrid workflows: AI alongside rules, search, and human processes
The most successful systems don’t replace everything with AI; they weave it into existing components. In practice, that means hybrid ai and traditional apis: search results fed into LLMs, rules engines constraining AI decisions, and human approval flows on top.
Take invoice processing. OCR and rules can handle most structured cases. For messy, unstructured invoices, AI models can extract and normalize entities, but their outputs pass through rules and, for low-confidence cases, human review. This is intelligent automation, not blind automation—a form of ai process automation that keeps risk in check.
These custom ai workflows often benefit from dedicated workflow and process automation services that orchestrate AI tasks alongside deterministic steps. Done well, AI becomes a powerful collaborator inside your existing processes, not a rogue system off to the side.
High-volume patterns for SaaS and platforms
For SaaS platforms, scale adds another layer of complexity. You’re not just calling AI APIs; you’re doing it across thousands of tenants with different needs, budgets, and risk profiles. This is where the best ai api integration services for saas platforms distinguish themselves.
You’ll need tenant-aware throttling and per-tenant configuration of AI features—different models, prompts, or limits for different plans. Workloads might be sharded across providers or model types to optimize quality of service and cost. You may route premium tenants to higher-quality models and budget-conscious ones to cheaper options.
MLOps-style practices apply even when you’re using third-party LLM APIs: prompt and model versioning, shadow testing new prompts, and continuous ai model monitoring. For ai api integration services for saas platforms, these become foundational capabilities, not nice-to-haves.
Build vs Buy: When to Use Managed AI API Integration Services
So far we’ve talked about patterns. The practical question is: should your team build all of this in-house, or partner with a managed ai api integration service provider that already bakes these patterns in?
The hidden costs of DIY AI API integration
The first hidden cost of DIY is ongoing prompt and model management. Every prompt you ship becomes a mini-codebase: it needs versioning, testing, and monitoring as models evolve. Over time you accumulate dozens or hundreds of prompts, each with its own quirks and latent bugs. That’s real ai development cost, not a one-time experiment.
Then there’s operations: monitoring model changes, debugging edge cases, managing rate limits and cost spikes, and keeping observability dashboards healthy. On-call rotations absorb “soft” AI incidents—latency fluctuations, subtle drift, quality regressions—that don’t show up as hard errors but erode user trust.
Organizationally, knowledge silos form. Each feature team reinvents retry patterns, validation, and governance. Before long, your enterprise ai solutions look like a patchwork of bespoke integrations instead of a coherent platform.
When a managed integration partner makes sense
Bringing in a specialist ai solutions provider starts to make sense when AI demand is spreading across teams, SLOs are tightening, or governance and compliance are non-negotiable. If multiple squads want to build AI features but none owns reliability, you’re a prime candidate for a managed approach.
A good managed ai api integration service provider comes with pre-built patterns for latency, validation, observability, and governance. They help you move from fragile POCs to robust systems faster, with fewer painful incidents along the way. It’s the same logic that drove companies to adopt specialized payments or auth providers instead of rolling their own forever.
For ai api integration services for enterprises, this often looks like a shared orchestration platform that different teams plug into, with consistent guardrails and governance. Your internal teams focus on product logic; the partner focuses on making AI calls safe, fast, and predictable.
How Buzzi.ai designs, implements, and operates AI-aware integrations
At Buzzi.ai, we start with an AI discovery and architecture assessment: which use cases matter, what constraints (latency, compliance, budget) exist, and how your current systems are wired. From there, we design an AI-aware orchestration and integration layer tailored to your stack.
Our work spans ai agent development, AI-aware web and mobile app integration, and workflow automation. We build the orchestration services, validation layers, observability, and policy engines that keep your AI features on the rails. Then we stay involved to monitor behavior, adapt to model changes, and optimize over time.
One anonymized example: a SaaS platform came to us with a flaky AI support assistant that was causing SLO breaches. We wrapped their LLM calls in an orchestration service with adaptive timeouts, validation, caching, and human-in-the-loop fallbacks. Within weeks, they’d stabilized latency, cut hallucination-driven tickets, and regained confidence in rolling AI features out to more tenants.
Conclusion: Make AI APIs Boringly Reliable
AI APIs are not just another REST dependency. Treat them that way and you get features that impress in demos and misbehave in production. Their probabilistic nature means old integration habits—thin wrappers, naive retries, minimal validation—are no longer enough.
Production-grade ai api integration services depend on orchestration layers, latency-aware patterns, validation and guardrails, and robust observability. Governance, safety, and cost control must be encoded directly into your integration layer, not bolted on through documents and wishful thinking. The best architectures blend AI APIs with existing microservices, rules, and human workflows to create systems that are both powerful and trustworthy.
If you’re wondering whether to build all this yourself or lean on a managed ai api integration service provider, start small: audit one critical AI feature. Where are you assuming determinism? Where are you missing validation or ignoring latency envelopes and governance? If you’d like a structured way to answer those questions and design a phased path from POC to production, we’d be happy to talk—our AI-enabled web application development services are built exactly for this bridge from prototype to reliable product.
FAQ
Why do traditional REST integration patterns fail with AI APIs?
Traditional REST patterns assume deterministic behavior: same input, same output, clear error codes when something breaks. AI APIs, especially LLM-based ones, are probabilistic and can return different outputs—even incorrect or unsafe ones—while still responding with HTTP 200. Without extra layers for validation, fallbacks, and observability, patterns that work fine for payments or messaging become brittle when applied to AI.
How are AI APIs like LLMs different from deterministic services?
LLM APIs sample from a probability distribution instead of executing fixed business logic, so outputs vary in structure, tone, and factuality. They can hallucinate, hit safety filters, or change behavior when the provider updates the model, all without code changes on your side. That’s why they require orchestration, validation, and monitoring on top of the usual HTTP integration basics.
What are the best AI API integration patterns for managing latency and errors?
Effective patterns include adaptive timeouts, capped retries, and circuit breakers tuned for high-variance AI endpoints. Combining synchronous and asynchronous pipelines, with clear envelopes for acceptable latency and quality, keeps user experience smooth. You also want graceful fallbacks—cached answers, downgraded responses, or human escalation—when those envelopes are exceeded.
How can I validate and sanitize AI API outputs before using them?
Treat AI outputs like untrusted user input. Enforce structured formats (e.g., JSON schemas), run business-rule checks against your own databases, and add semantic or grounding checks to catch hallucinations. Content moderation filters help block toxic or policy-violating outputs, and low-confidence cases should either be retried with better prompts or routed to human review.
When should I use synchronous vs asynchronous AI API integration?
Use synchronous calls for lightweight, interactive features like chat, autocomplete, or small transformations where users expect immediate feedback. For heavy tasks—long documents, batch processing, or complex analytics—prefer asynchronous patterns with queues, workers, and progress updates. Many teams combine both: a quick synchronous preview followed by deeper asynchronous refinement.
How do I design fallbacks and retries for unreliable AI API responses?
Start by making requests idempotent so retries don’t cause duplicate side effects. Use capped, backoff-based retries and circuit breakers that stop hammering the provider when failure rates spike. On the fallback side, plan semantic downgrades (simpler answers), use cached or rule-based responses where possible, and route high-risk or low-confidence cases to human agents instead of forcing an AI answer.
What architectures work best to integrate AI APIs into an existing SaaS platform?
A strong pattern is to wrap AI capabilities in dedicated microservices with deterministic contracts that other services consume. Under the hood, these services orchestrate calls to various AI providers, search, and rules engines, plus human-in-loop steps where needed. This keeps your core platform stable while still letting you evolve AI internals quickly, or plug in partners like Buzzi.ai for specialized AI chatbot and assistant development.
How can I monitor AI API behavior and detect hallucinations in production?
Set up observability that logs prompts, outputs or samples, model versions, latency, and validation results. Track metrics like error rates, timeout rates, and hallucination or low-grounding incidents over time. Pair this with dashboards and alerts so your team can spot drift, regressions, and unusual behavior quickly instead of relying on user complaints.
What governance and compliance issues arise with enterprise AI API integration?
Key issues include where data is processed, how long it’s retained, whether vendors use your data for training, and how PII or regulated data is handled. You’ll need policy-aware routing to ensure sensitive data stays in compliant environments, plus encryption, masking, and strict access controls around logs and prompts. Frameworks like the NIST AI RMF and the EU AI Act provide guidance, but those policies must be implemented directly in your orchestration layer.
When does it make sense to use a managed AI API integration service provider like Buzzi.ai instead of building in-house?
It makes sense when AI demand is growing across teams, reliability and SLO expectations are high, or you operate in regulated environments where mistakes are costly. A partner like Buzzi.ai brings reusable orchestration, validation, and governance patterns so you’re not reinventing them feature by feature. That lets your engineers focus on product value while we handle the complexity of keeping AI integrations fast, safe, and compliant.


